
Kotlin union vs flatten
Introduction
Kotlin에서 2개 이상의 배열을 합쳐 하나의 배열로 반환해야하는 기능을 구현하는 상황에서 union함수를 사용할지 flatten함수를 사용할지 고민을 한적이 있다. 당시에는 flatten을 사용하였지만 (union을 사용할 경우 반환 형식이 Set이기 때문에 다시 toList함수를 호출해야 해서 flatten을 사용하였다.union과 flatten을 사용하였을 때 퍼포먼스라던지 메모리 사용량이 얼마나 차이가 나는지 궁금해서 정리해본다.
union
Kotlin의 API 문서 1.3버전 에서 보면 union은 아래와 같이 정의되어 있다.
두 컬랙션의 모든 중복이 제거된 요소들의 집합
set을 반환한다. 반환된set은 요소의 반복 순서를 보장한다.
먼저 반환값에서 중복이 제거되는지 먼저 확인해보았다.
val a = listOf(1,1,3,4,4,4,5,6)
val b = listOf(7,8,9,10,11,12)
val c = a.union(b)
// [1, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
println(c)
순서를 보장하는지도 확인해 보았다.
val a = listOf('a', 'b', 'c', 'd')
val b = listOf('c', 'f', 'b', 'z')
val c = a.union(b)
// [a, b, c, d, f, z]
println(c)
Context collection의 값을 먼저 나열한 다음 union 함수의 매개변수로 받은 collection의 값들을 나열하는 순서로 표시된다. 중복의 경우 먼저 정의된 값은 표시되고 뒤에 중복된 값은 제거되면서 순서에 표시되지 않는다.
flatten
Kotlin의 API 문서 1.3버전 에서 보면 flatten은 아래와 같이 정의되어 있다.
주어진 배열 / Iterable 인터페이스의 모든 배열 / Iterable 인터페이스를 단일 목록으로 반환한다.
이중으로 된 배열이 하나의 배열로 나타나는지 확인해 보겠다.
val arr = arrayOf(
arrayOf(1,2,3,4,5,6),
arrayOf(7,8,9,10,11,12)
)
val list = arr.flatten()
// [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
println(list)
flatten은 중복을 제거하지 않는다.
val arr = listOf(
listOf(1,1,1,2,3,4,5,6),
listOf(7,8,9,10,11,11,11,12)
)
val list = arr.flatten()
// [1, 1, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 11, 11, 12]
println(list)
따로 명시되어 있진 않지만 순서도 보장해준다.
val arr = listOf(
listOf("a", "c", "c", "z"),
listOf("b", "d", "f", "w"),
listOf("r", "k", "u", "z")
)
val list = arr.flatten()
// [a, c, c, z, b, d, f, w, r, k, u, z]
println(list)
Compare performance
그럼 union과 flatten의 결과 반환 속도를 확인해보자.
객관적인 테스트가 될지 모르겠지만대량의 숫자 Collection들을 생성해서 하나의 Collection을 반환하는 기능을 테스트 해보았다.
테스트 방법은 비교하기 쉽게 대량의 데이터를 주고 실행속도를 비교하는 방법으로 진행했다. 실행결과는 10번정도 번갈아가면서 테스트하였으며 캐시는 특별히 고려하지 않았다. Windows10에서 openjdk-1.8버전을 사용하였다.
Given 2 list without duplicate
100만개의 목록을 가진 중복값이 없는 2개의 배열을 비교해 보았다.
val listA = (1..10000000).toList()
val listB = (10000001..20000000).toList()
val timeMillis = measureTimeMillis {
listA.union(listB).toList()
}
// 5531 ~ 13138
println(timeMillis)
val listA = (1..10000000).toList()
val listB = (10000001..20000000).toList()
val timeMillis = measureTimeMillis {
val list = listOf(listA, listB)
list.flatten()
}
// 200 ~ 256
println(timeMillis)
비교결과 flatten이 union에 비해 빠르게 적용됨을 알 수 있었다.
Given 2 list with duplicate
그럼 만약 100만개의 목록에 중복된 값이 존재하는 경우에는 어떻게 될까? 목록 A와 목록 B을 동일한 값으로 생성해서 비교해 보았다.
val listA = (1..10000000).toList()
val listB = (1..10000000).toList()
val timeMillis = measureTimeMillis {
listA.union(listB).toList()
}
// 4301 ~ 4938
println(timeMillis)
두개의 목록의 개수가 같음에도 union함수의 실행시간이 중복값이 없는 경우보다 많이 줄어든 것을 알 수 있다.
val listA = (1..10000000).toList()
val listB = (1..10000000).toList()
val timeMillis = measureTimeMillis {
val list = listOf(listA, listB)
list.flatten()
}
// 192 ~ 217
println(timeMillis)
flatten함수는 중복값이 있으나 없으나 비슷한 속도를 보여준다.
만약 flatten이 union과 같이 중복을 제거해야 한다면 성능은 얼마나 차이가 날까?
distinct함수를 사용해보았다.
val listA = (1..10000000).toList()
val listB = (1..10000000).toList()
val timeMillis = measureTimeMillis {
val list = listOf(listA, listB)
list.flatten().distinct()
}
// 6770 - 7540
println(timeMillis)
중복값을 제거하니 오히려 flatten이 union보다 느린 속도를 보여준다.
Given more than 2 list without duplicate
이번에는 2개의 Collection이 아닌 다수의 Collection을 하나의 Collection으로 반환할때 속도를 비교해 보고자 한다.
Collection의 개수는 10개로 하였다. 10개로 결정한 이유는 특별히 없고 많아질 수록 속도가 비슷한 비율로 증가할것처럼 보여서 특별히 고민하지는 않았다.
val list1 = (1..1000000).toList()
val list2 = (1000001..2000000).toList()
val list3 = (3000001..4000000).toList()
val list4 = (5000001..6000000).toList()
val list5 = (7000001..8000000).toList()
val list6 = (9000001..10000000).toList()
val list7 = (1100001..11000000).toList()
val list8 = (1300001..12000000).toList()
val list9 = (1500001..14000000).toList()
val list10 = (1700001..16000000).toList()
val timeMillis = measureTimeMillis {
list1.union(list2)
.union(list3)
.union(list3)
.union(list4)
.union(list5)
.union(list6)
.union(list7)
.union(list8)
.union(list9)
.union(list10)
.toList()
}
// 20905 ~ 24815
println(timeMillis)
val list1 = (1..1000000).toList()
val list2 = (1000001..2000000).toList()
val list3 = (3000001..4000000).toList()
val list4 = (5000001..6000000).toList()
val list5 = (7000001..8000000).toList()
val list6 = (9000001..10000000).toList()
val list7 = (1100001..11000000).toList()
val list8 = (1300001..12000000).toList()
val list9 = (1500001..14000000).toList()
val list10 = (1700001..16000000).toList()
val timeMillis = measureTimeMillis {
val list = listOf(
list1, list2, list3, list4, list5,
list6, list7, list8, list9, list10
)
list.flatten()
}
// 7147 ~ 7977
println(timeMillis)
예상했을 수도 있겠지만 flatten함수가 union함수보다 빨리 결과를 반환해 주는것을 볼 수 있다.
Given more than 2 list with duplicate
2개 이상의 중복된 Collection들을 하나의 Collection으로 반환하는 경우도 확인해보자.
val list1 = (1..1000000).toList()
val list2 = (1..1000000).toList()
val list3 = (1..1000000).toList()
val list4 = (1..1000000).toList()
val list5 = (1..1000000).toList()
val list6 = (1..1000000).toList()
val list7 = (1..1000000).toList()
val list8 = (1..1000000).toList()
val list9 = (1..1000000).toList()
val list10 = (1..1000000).toList()
val timeMillis = measureTimeMillis {
list1.union(list2)
.union(list3)
.union(list3)
.union(list4)
.union(list5)
.union(list6)
.union(list7)
.union(list8)
.union(list9)
.union(list10)
.toList()
}
// 1413 ~ 1591
println(timeMillis)
val list1 = (1..1000000).toList()
val list2 = (1..1000000).toList()
val list3 = (1..1000000).toList()
val list4 = (1..1000000).toList()
val list5 = (1..1000000).toList()
val list6 = (1..1000000).toList()
val list7 = (1..1000000).toList()
val list8 = (1..1000000).toList()
val list9 = (1..1000000).toList()
val list10 = (1..1000000).toList()
val timeMillis = measureTimeMillis {
val list = listOf(
list1, list2, list3, list4, list5,
list6, list7, list8, list9, list10
)
list.flatten()
}
// 79 ~ 98
println(timeMillis)
val list1 = (1..1000000).toList()
val list2 = (1..1000000).toList()
val list3 = (1..1000000).toList()
val list4 = (1..1000000).toList()
val list5 = (1..1000000).toList()
val list6 = (1..1000000).toList()
val list7 = (1..1000000).toList()
val list8 = (1..1000000).toList()
val list9 = (1..1000000).toList()
val list10 = (1..1000000).toList()
val timeMillis = measureTimeMillis {
val list = listOf(
list1, list2, list3, list4, list5,
list6, list7, list8, list9, list10
)
list.flatten().distinct()
}
// 313 ~ 351
println(timeMillis)
중복값을 가지는 경우 union과 flatten 두 함수 모두 큰 비율로 속도가 줄어드는것을 확인 할 수 있다.
Compare JVM usage
union과 flatten의 속도를 비교해 보았는데, 속도만 비교할 것이 아니라 메모리 사용량도 함께 보고 비교해보면 함수를 선택하는데 좀더 도움이 될것 같아 메모리 사용량을 비교해 보겠다.
메모리 사용량 확인은 VisualVM Launcher를 사용하였다.
차이를 보기 위해 다수의 Collection을 하나의 Collection으로 반환하는 케이스로 확인하였다.
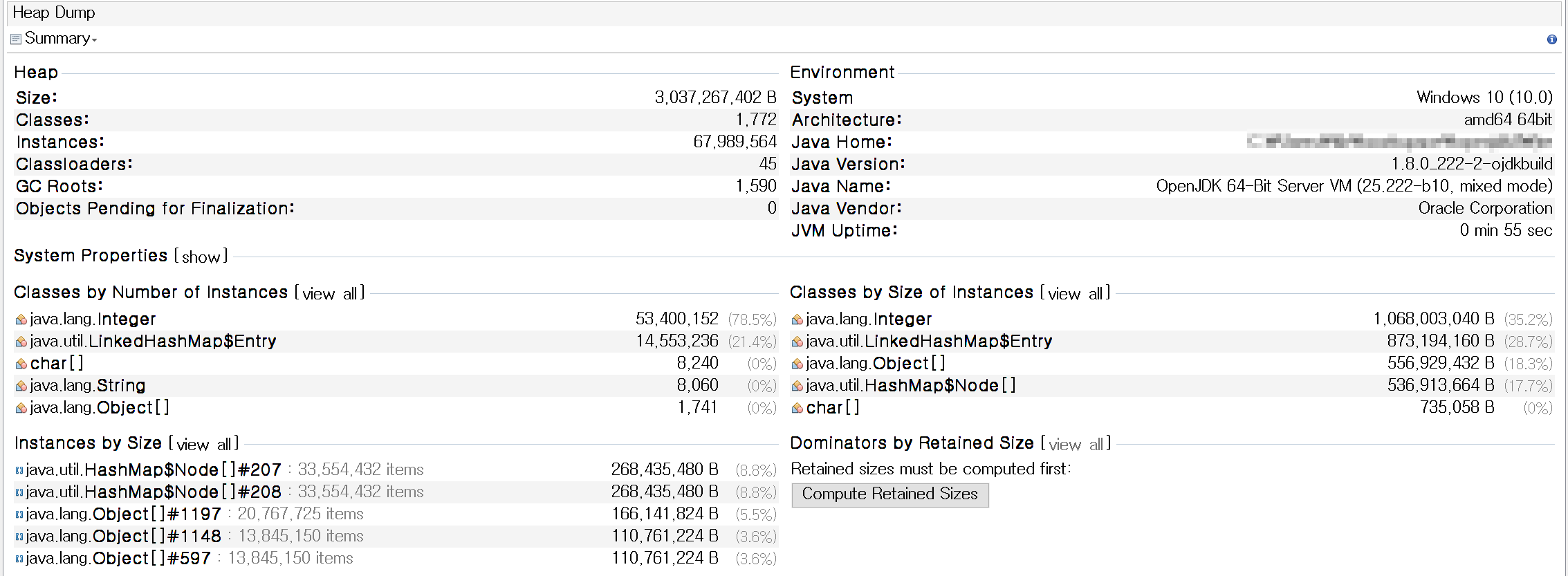
union heap dump
flatten heap dump
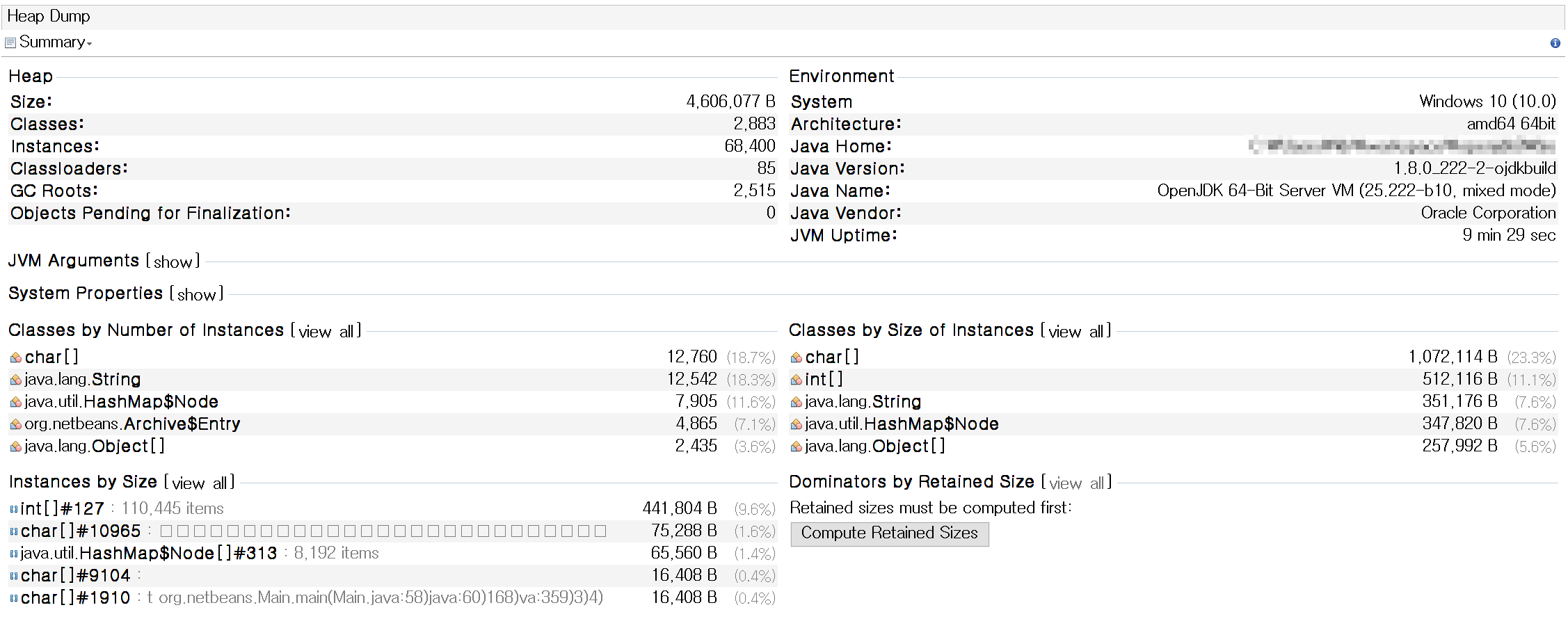
메모리 사용량을 보아도 union이 flatten보다 많은 메모리를 사용하고 있음을 볼 수 있다.
Conclusion
이번글에서 union과 flatten함수를 사용할 때 동일한 Collection들을 주고 하나의 Collection을 반환하게 하였을 때 성능을 비교해보았다. 중복되지 않은 데이터를 제공해 주었을 때에는 union보다 flatten함수가 더 나은 성능을 보여주었다. 하지만 중복을 제거해야 하는 경우에는 데이터의 양에 따라 차이가 있을 수 있겠지만 union이 더 좋은 성능을 보여줄 때도 있었다.
업무에서 이와 유사한 케이스로 하나 이상의 Collection을 병합해야 하는 경우 참고해서 사용하면 좋을 것 같다.
https://kotlinlang.org/api/latest/jvm/stdlib/kotlin.collections/union.html
https://kotlinlang.org/api/latest/jvm/stdlib/kotlin.collections/flatten.html