
2022년 7월 개발일지
주요 과제였던 주문/채팅 프로젝트가 마무리되고나서 산발적으로 다양한 규모의 프로젝트들이 생겨나기 시작했다. 그러면서 프로젝트의 관리 이슈가 대두되기 시작하였다. 사실 프로젝트관리에 대한 이야기는 내가 여기에 입사하고부터 수 없이 발의되고 변경되었다. 그러다가 정비기간을 가지면서 프로젝트 관리에 대한 이슈는 한동안 없었는데, 다시 프로젝트가 여러개가 돌아가기 시작하니 효율적으로 프로젝트를 관리하기 위한 이야기가 나오는듯 하다.
사실 딱 이거다라고 생각되는 해결책이 없기도 하다. 스크럼 형태로 프로젝트를 진행하다보면 일정에 대한 관리가 조금 수월하지만 인원이 한정적이다보니 동시에 여러 프로젝트를 진행해야 하는 상황에서는 작업에 대한 공수 예측을 하기 힘들다는 단점이 있다. 반면 칸반 형태로 프로젝트를 진행하다보면 작업에 대한 공수를 미리 측정하여 정해진 기간에 완수하여야 한다는 부담은 줄어들지만 관리자나 유관부서 입장에서는 언제 원하는 기능의 개발이 완료되는지 알기 어렵기 때문에 관리의 불편함이 있다는 단점이 있다.
결국 우리 팀에서는 스크럼 형태로 프로젝트를 진행하기로 결정하고 다만 정석대로 스프린트를 운영하기 보다는 스프린트 기간내에 다른 이슈들이 추가될 수 있는 여지(?)를 두고 운영하고 있다. 근데 이 여지(버퍼시간이라고 부른다)에 대한 인식이 구성원들간의 차이가 있는 듯 하다. 나는 버퍼시간이 개발에 대한 정확한 공수를 하기 어려워 100%의 작업 예상 공수를 두기보다 80%~90%의 예상공수를 두어 혹시 모를 기술적인 이슈를 대응할 시간을 마련해 두는 것이라 생각하였다고 생각했다. 장애나 긴급한 운영이슈에 대한 대응 시간이 있을 수 있으니 이부분에 대한 시간도 마련하는 것이라 생각할 순 있는데 나는 이 시간을 마련하는 것은 무리가 있다고 생각이 든다. 얼마나 발생할지 모르는 운영이슈나 장애를 위해서 작업 공수를 미리 뻬둔다면 정작 필요한 기능 개발에 대한 공수를 지나치게 적게 잡을 수 있다는 생각이기 때문이다. 그래서 혹시나 장애나 긴급한 운영이슈가 너무 많이 발생해 스프린트에 계획한 일을 못하는 상황이 생기게 되는 상황은 어쩔 수 없이 감수해야한다고 생각한다. 그런일이 지속적으로 생긴다면 이를 개선하기 위한 노력을 이어가야 하지 않나 싶다.
한편, 이 버퍼시간에 대해 나와 조금 다르게 생각하시는 분들도 계신것 같다. 버퍼시간을 이용해 계획되지 않은 일들을 추가적으로 할 수 있다고 생각해서 스프린트 플래닝 때 계획하지 않은 이슈(버그나 긴급 처리 이슈를 제외한)를 요청하는 경우이다. 나는 이러한 방식에 대해서는 반대하는 입장인데, 이렇게 버퍼시간을 이용하기 시작하면 작업자들은 작업에 대한 공수를 더욱더 보수적으로 측정하려고 할 것이고 버퍼시간이 점점더 비대해지는 상황이 생기게 될 것이기 때문이다. (버퍼시간을 적게 잡아달라고 요청한다고 작업자가 적게 잡지는 않을 것이다)
그래서 나는 이와 같은 문제를 해결하기 위해서는 스크럼이든 칸반이든 상관없이 만들어야할 기능에 대한 요구사항이 명확하게 나와서 공수 예측을 보다 쉽게 하고 계획되지 않은 이슈가 발생하는 것은 어쩔 수 없으니 이를 좀더 효과적으로 처리하기 위한 방법을 모색해야한다고 생각한다. 한사람이 여러 스프린트를 참가해야 하는 상황이라면 스크럼을 사용하는게 큰 의미를 가지기 힘들다 생각한다. 차라리 칸반으로 운영하면서 작업자가 수행해야할 일들의 예상 완료일시를 측정하여 그것들을 모은 결과를 토대로 언제 배포가 가능한지 가늠하는게 낫지 않을까. 그럴려면 프로젝트를 관리할 인력이 필요하게 될것이다.
반대로 프로젝트를 관리할 인력이 부재하다면 팀을 나누고 각 팀이 하나의 스프린트를 운영하면서 제품에 필요한 기능들을 목록화 한 후 주기적으로 스프린트를 수행하면서 완성시켜가는 방법을 사용하는 것도 좋아보인다고 생각한다. 우리는 스쿼드라고 표현하는 이 조직은 본인들이 맡고 있는 제품에 대한 이해도가 높기 때문에(짧지 않은 기간동안 이 조직이 유지된다면) 비록 요구사항에서 불분명한 것들이 있다고 하더라도 모두가 이 불분명함을 메울 수 있고 목표가 명확하고 요구사항이 명확하니 작업자들의 공수 산정이 좀더 정밀해질 것이라 생각이 든다.
다음으로 프로젝트가 이렇게 나누어지면서 백엔드 개발챕터의 관리 방법에 대한 고민도 많이 하게되었다. 사실 언어전환 프로젝트를 수행하거나 주문/채팅 프로젝트를 수행할 때에는 백엔드 모두가 하나의 프로젝트를 바라보고 작업하고 있었기 때문에 내가 관리할 수 있는 범위 내에서 설계도 하고 코드 리뷰도 수행하면서 품질을 챙기려는 노력을 하였다. 하지만 이제 프로젝트가 나뉘어지면서 내가 모든걸 추적하고 관리하려는 것이 나의 욕심임을 느끼게 되었다. 그리고 이전에는 코드리뷰를 좀더 적극적으로 하면서 모든 코드에 관여하려는 욕심을 부렸는데, 지금와서 보니 너무 나의 스타일을 고집하거나 팀원들의 자유도를 너무 구속한게 아닌가 싶기도 하다. 그래서 요즘에는 코드리뷰를 빡세게 하려고 하기보다 특별한 문제 없으면 넘어가려고 하고 있다. 여전히 아쉬운 부분들이 보이긴 하지만 좋은 코드리뷰에 대한 고찰에서 적었던 것처럼 코드리뷰의 목표는 코드레벨을 A로 만드는 것이 아니니 좀 더 팀원들에게 주도성을 주는게 좋아 보인다.
다만 가끔 설계에 대한 아쉬운 부분들이 발견되면서 프로젝트 중간에 변경을 요청하는 경우가 생기는데 이러한 일이 생기지 않도록 하기 위해 어떻게 하면좋을 지 고민중이다. 이전에는 설계를 다같이 하기 때문에 이러한 이슈는 없었는데 프로젝트가 나누어지면서 각자에게 설계를 맡기고 진행하다보니 이러한 상황 종종 발생하게 되었다. 더 좋은 설계가 있는데 그냥 넘어가는것은 코드레벨을 A로 만드는 것과는 다르다고 생각한다. 잘못 설계된 API는 프론트에서 사용하는 순간 변경하기도 어렵고 제품의 품질에도 직접적으로 연관이 있기 때문이다. 이 부분을 해결하기 위해 한번 논의를 해봐야겠다.
아래는 7월동안 정리한 이슈 내용들이다.
Lottie
Lottie는 에어비앤비에서 만든 오픈소스라이브러리로 무료 애니메이션 리소스를 다운로드 해서 쉽게 커스터마이징, JSON 파일로 공유할 수도 있는 라이브러리이다. 무엇보다 용량이 적고 JSON으로 공유할 수 있어서 용량이 큰 GIF를 공유할때의 불편함을 많이 해소할 수 있을 듯 하다.
Deprecate WebSecurityConfigurerAdapter
Spring Security 5.7.0-M2 버전 이후부터 우리가 흔하게 사용해오던 WebSecurityConfigurerAdapter가 deprecated 되었다. 관련된 대응 방법은 Spring Security without the SebSecurityConfigurerAdapter 글에 적혀있다. 요즘 시큐리티 관련글 보면 WebSecurityConfigurerAdapter가 적용된 글들이 많은데 이와 관련해서 새로운 방식으로 처리하는 방법에 대한 튜토리얼 블로그를 작성해봐야겠다.
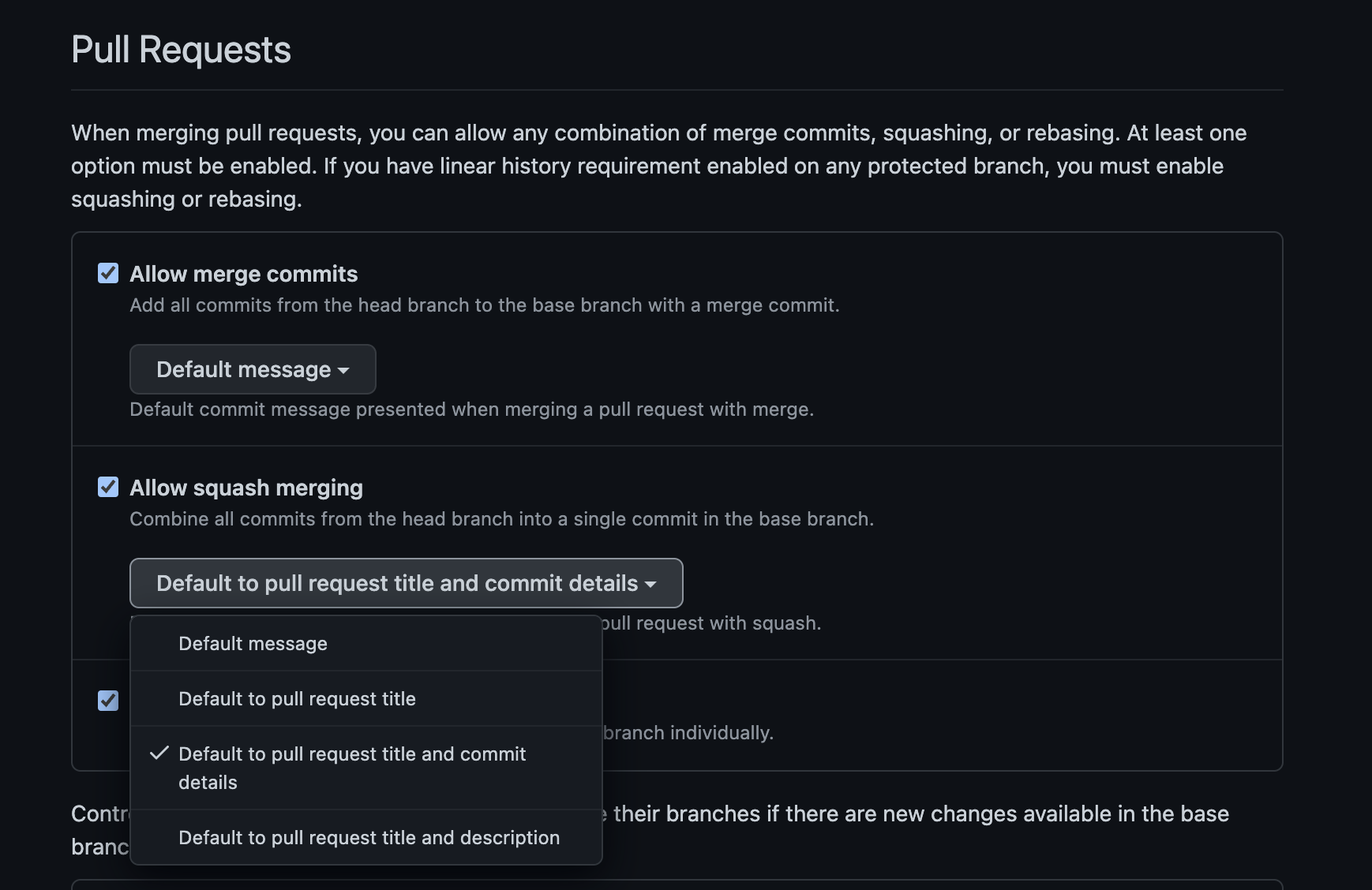
스쿼시 병합 시 PR 제목으로만 병합하기 설정
기존에는 하나의 커밋으로 PR을 작성한 경우 스쿼시 병합하면 PR의 제목이 아닌 커밋의 제목으로 병합이 되었다. 그러다보니 커밋이 여러개인 PR인 경우는 PR의 제목이 병합 커밋의 제목으로 되는데 일관성이 떨어지는 불편함이 있었다. 하지만 아래와 같이 깃헙 설정이 추가 되었고 이 설정을 통해 선택을 할 수 있게 되었다.
리엑트를 이용한 JWT 인증
관리자로 리엑트를 이용한 JWT 인증 구현을 고민하다가 아래와 같은 블로그글이 있어서 기억해두면 좋을 것 같아 가져와서 적어본다.
https://hasura.io/blog/best-practices-of-using-jwt-with-graphql/
실제 구현은 여기처럼 복잡하게 하진 않았지만 많은 도움이 되었다.
트렁크 기반 개발에서 발생하는 문제점을 해결하기 위한 전략 2가지
-
Branch by Abstraction
말그대로 추상화를 통해 기능에 대한 분기를 하는 방식이다. 아직 기능이 미 구현되었거나 운영환경에서 사용되지 않아야할 코드를 추상화를 통해 분기처리해서 기능이 꺼진 상태해서는 해당 기능이 동작하지 않는 구현체를 기능이 켜진 상태에서는 기능이 동작하는 구현체로 교체하는 방식이다.
스위치를 켜고 끌 때 변경하는 커밋이 추가되어야 한다는 점과 배포가 일어나야 한다는 점이 단점이긴 하지만 별다른 리소스 추가 없이 코드만으로 스위치를 만들어낼 수 있기에 좋아보인다.
-
Feature flags
트렁크 기반 개발에서 흔하게 사용하는 방법으로 구현할 기능에 스위치 기능을 만들어 두고 원하는 시기에 기능을 사용하도록 할 수 있는 방식이다. 스위치 기능을 구현하는 방식은 다양한데 배포 없이 단순히 기능을 켜고 끄길 원한다면 외부 리소스 (DB 등)을 이용해야 한다.
두개의 해결방법만 보면 트렁크 기반 개발이 아주 이상적인것처럼 보이나 개인적으로는 이 두방법만으로도 복잡성을 해결하기엔 어려워 보인다. 여러 프로젝트가 섞여서 개발되는 팀의 경우 (규모가 크지 않아도 여러 프로젝트가 진행될 수 있다) 이러한 해결책을 사용하기 위해서는 상당히 많은 고민과 우회방법을 모색해야 한다.
JJWT 의존성 에러
jjwt 쓸때 javax/xml/bind/datatypeconverter 에러가나면 아래 의존성을 추가해주면 된다. JAVA 11부터 기본으로 넣어주지 않는다고 한다. (메이븐에 같이 좀 넣어주지…)
implementation("javax.xml.bind:jaxb-api:{버전}")
인터페이스 함수에 @Async를 사용하는 경우
인퍼테이스 함수에 @Async를 추가하면 proxy 타입에 따라 동작하기도 하고 안하기도 한다. 이러한 방식은 권장되지 않는데 그이유는 첫번째가 동작상식이 proxy에 따라 결정되기 때문에 명확하지 않는 것이고 두번째는 인터페이스의 주요 목적은 “어떻게 하는지”가 아니라 “무엇을 하는지”이기 때문이다. (덕분에 좋은 문구를 배웠다.)
https://stackoverflow.com/questions/9109126/spring-async-annotation-on-interface-methods
JPA OneToOne fetch type
JPA의 OneToOne은 기본 fetch type이 EGER 로딩이다. LAZY로 바꿔도 지연로딩이 되지 않는 경우가 있는데 바로 optional이 false이면 무조건 호출한다. 반대로 optional이 true이면 지연로딩을 할 수 있다. 1:1 관계에서 무조건 not null이라도 무조건 부르지 않을 수 있는데…LAZY로딩 지원해주지….
linux에서 프로세스 죽이는 스크립트
최근에 실행중인 프로세스를 종료시키고 다시 시작하는 스크립트를 작성할 일이 있어서 작성하다가 이전에는 kill 명령어만 날린 뒤 종료 되는것을 고려하지 않았었는데 재시작을 하려니 종료가 완료되었음을 확인할 필요가 있게 되었다. 그래서 kill -0를 활용하는 방법을 배워 적어본다.
#!/bin/bash
echo '시작'
PS_NAME=test
PS_CNT=`ps -ef | grep $PS_NAME | wc -l`
echo $PS_CNT
if [ $PS_CNT -gt 1 ] ; then
PID=`ps -ef | grep $PS_NAME | awk '{print $2}' | head -1`
kill $PID
while $(kill -0 $PID 2>/dev/null); do
echo wait kill process[$PID]
sleep 1
done
fi
Spring Data DynamoDB
RangeKey 오류가 있다…ㅠㅠ 솔직히 Spring Data DynamoDB는 실무에서는 쓰기가 좀 아쉬운 부분이 많은 듯 하다.
https://github.com/derjust/spring-data-dynamodb/issues/279
Elastic Search Client
Elastic Search SDK에서 RestHighLevelClient를 deprecated 시키고 새로운 클라이언트인 ElasticsearchClient를 추가했다. 하지만 Spring Data Elasticsearch에서는 이에 대한 대응이 아직 되지 않아 지원되지 않고 있다.