
2023년 3월 개발일지
3월 중순이 지나면서 날씨가 많이 따뜻해졌다. 그래서 비가오거나 약속이 있는게 아니라면 되도록 자전거로 출근을 하려고 노력했다. 환절기라 갑자기 추워지기도 하였지만 겨울용 져지도 장만했기에 자전거를 타는데에는 문제가 없었다. 집에서 회사까지 8km정도 되는 거리라 부담없이 출퇴근하기 좋다. 다만 공도를 달려야하기 때문에 신호대기도 많고 달리는 자동차 옆에서 함께 달려야하기 때문에 조금 불편함이 있다. 조금 돌아가긴하지만 자전거 도로가 있긴한데 그쪽으로도 한번 가봐야겠다.
아래 사진은 동네에 유명한 프레츨 가게가 생겨서 회사에 가는길에 사서 가며 찍은 사진이다. (자덕이 되어가면서 자전거 사진을 많이 찍게된다던데…)

자출의 문제는 땀인데, 날씨가 점점 더워지면서 땀을 많이 흘리게될것이라 예상된다. 지금 다니는 헬스장이 5월에 끝나는데, 헬스장이 끝나고나면 회사사람들이 다니는 회사앞 헬스장으로 바꿔서 아침에 출근하고 운동한다음 샤워하고 출근하는 형태로 바꿔봐야 겠다.
명세표 정리기능 서비스를 중지하면서 명세표 관련 테스트 코드를 모두 정리했다. 운영코드도 함께 정리해야하는데 서비스를 중지하였지만 기존 사용자를 배려해서 기존 명세표 데이터를 엑셀로 받아볼 수 있는 기능을 남겨둔터라 6월까지는 운영코드를 제거할 순 없었다. 일단 테스트 코드는 제거되었으니 아쉬운데로 올해 계획했던 통합테스트에서 기능테스트로 테스트 전환을 시작하였다.
통합테스트에서 기능테스트로 전환을 계획하면서 기능 테스트에 대한 난이도로 인해 여러가지 고민들과 우려사항이 있었다. 그럼에도 불구하고 기능테스트가 가져다주는 안정감이 통합테스트에 비해 월등히 높았기에 여유가 될때마다 차근차근 진행하려고 한다. 아마 기능테스트 전환이 마무리되면 블로그를 쓸 예정인데 그동안 생겼던 일들을 잘 정리해놔야겠다.
출판사에서 추가 책 집필 제안이 들어왔다. 코틀린 + 스프링부트와 관련한 주제가 마음에 들어 써볼까 고민했었는데, 아직 작년에 썼던 책이 출판되지도 않았고 올해 2분기부터 조금 바빠질 수도 있어서 고민끝에 올해 하반기쯤 집필여부를 다시 고민해보기로 하였다.
작년부터 진행중이던 책 집필은 디자인과 표지 시안들이 나오면서 얼추 마무리되어가는 모양새다. 빨리 출판이되면 좋겠다라는 생각과 함께 혹시나 혹평을 받을까봐 걱정이 되기도 하다. 책이 잘팔리길 기대하는건 너무 욕심이려나…
정리서비스를 중지하면서 앱의 홈화면이 함께 개편하는 프로젝트를 진행하게 되었다. 대대적 개편이다보니 작업일정도 길게 잡히게 되었는데, 그러다보니 배포할때 이것저것 함께 배포하기 위해 정리서비스 중지 프로젝트 외 다른 프로젝트 작업들을 함께 끼워넣는 상황이 몇번 생기게 되었다. 그러다보니 QA의 RC가 5회차까지 가는 등 좋지 않는 상황이 펼쳐지게 되었는데, 이와 관련해서 4월에 열리는 워크샵때 업무방식에 대한 개선이야기를 하기로 하였다.
QA조직이 있는 우리 회사의 특성상 배포에 대한 안정감이 상당히 높지만 반면 배포에 대한 부담이 QA조직이 없는 팀에 비해 높은건 사실이다. 특히 앱의 경우에는 앱심사과정도 있으니 배포에 대한 부담감이 더 크다. 그러다보니 규모가 큰 프로젝트가 있는 경우 QA가 진행되는 동안 다른 배포를 할 수 없어 기다려야하는 상황이 종종 생기곤하는데 이때 관리자들은 기다리기보다 QA의 RC에 다른 프로젝트 작업을 함께 끼워서 내보내려는 선택을 하곤한다.
기능을 빠르게 출시하고 피드백을 받아 더 나은 가치를 계속해서 전달해야하는 스타트업의 특성상 관리자들의 선택은 당연하다 생각한다. 나는 이러한 선택이 문제가 아니라 이러한 선택을 할 수 밖에 없는 상황을 근본적으로 해결해야 한다고 생각한다. 즉, 프로젝트의 규모를 컴펙트하게 유지하고 초반에 요구사항 정의를 제대로해서 커뮤니케이션 비용을 줄이도록 하는게 중요하다.
당연한 이야기이지만 프로젝트를 진행하다보면 이 당연한게 지켜지지 않을 때가 있다. 처음에는 컴펙트하게 시작한 프로젝트가 진행되다보면 이해관계자들이 기능에 대한 이해도가 높아지게되고 혹시나 필요할지 모르는 요구사항들을 이야기하기 시작한다. 중요한건 프로젝트에 참가자들이 이러한 요구사항들을 필터링할 수 있어야 하는데 그러지 못하게 되면 프로젝트 규모가 조금씩 커지게 되는것이다. 요구사항 부분도 마찬가지다. 프로젝트 초기에 요구사항을 제대로 정의하지 못하고 시작하면 중간중간 챙기지 못한 부분들이 발견되게 된다. 또한 모호한 요구사항으로 인해 개발자, QA 엔지니어들의 부족한 요구사항을 채우기위한 커뮤니케이션 비용이 증가하게되고 프로젝트 일정이 담보되지 않거나 계획했던 일정에 추가적인 일정이 계속해서 추가되는 상황이 지속되게 된다. 요구사항이 모호하면 요구사항이 추가될 가능성도 높아지게 되는데, 그 이유는 명확한 방향이 잡혀있지 않기 대문에 이해관계자의 추가 의견들을 제대로 필터링하지 못하기 때문이다.
내가 생각하는 이러한 해결방법을 워크샵에서 이야기한다고 한순간에 해결되긴 힘들다고 생각한다. 누군가는 현재의 문제가 문제가 아니라고 생각할수도, 해결할려는 의지가 없을 수도 있기 때문이다. 어쩌면 제시하는 해결방법이 업무에 불편함만 더 가중시킨다고 생각할 수도 있다. 아무래도 요구사항을 초반에 잘 정의하는 것은 비용이 적지않은 활동이니까. 그럼에도 불구하고 지속적으로 문제점을 제기하고 해결하려는 노력을 계속하다보면 조금씩 나아지지 않을까라는 희망을 가져본다.
아래는 3월동안 정리한 이슈 내용들이다.
Test 코드에서의 @Async 코드 처리
테스트할 때 어려운 코드중 하나가 바로 @Async로 처리한 코드들이다. 비동기로 처리된 코드들은 동기적으로 실행되는 테스트 단언(Assertion)에서 검증되지 않기 때문이다. 그래서 가장 쉬운 처리방법인 Thread.sleep으로 처리하거나 Awaitiliy 등으로 처리하기도 한다.
나쁘지 않은 방법이지만 테스트 검증코드가 장황해진다는 단점이 있다. 그래서 이번에 기능 테스트에서 도입한 방법을 소개하려고 한다. 바로 SyncTaskExecutor를 활용하는 방법이다. 문서에서도 볼수 있다시피 테스트에서 활용하기 위한 TaskExecutor 구현체이다. 물론 운영환경과 테스트환경에 동작에 차이를 주기 때문에 앞서 말한 방법으로 처리하는게 좋다는 의견도 있다. 하지만 동기처리냐 비동기처리냐는 보통 기능적인 요인보다는 성능적인 요인으로 인해 적용하는 경우가 많다. 그래서 성능이 중요하지 않은 테스트에서는 동기적으로 동작하도록 설정하는것도 좋다라고 생각한다.
테스트 설정에서 아래와 같이 TaskExecutor를 정의하면 된다.
@TestConfiguration
class FunctionalTestConfig {
@Bean
@Primary
fun taskExecutor(): TaskExecutor {
return SyncTaskExecutor()
}
}
이렇게하면 @Async가 적용되어있는 함수에서도 동기적으로 동작하는 것을 볼 수 있다.
@Service
class FooService {
@Async
fun test(foo: Foo) {
println("2")
foo.flag = true
}
}
class Foo {
var flag = false
}
class FooServiceTest : FunctionalTestBase() {
@Autowired
private lateinit var fooService: FooService
init {
test("test") {
println("1")
val foo = Foo()
fooService.test(foo)
println("3")
foo.flag.shouldBeTrue()
}
}
}
-
설정 적용 전
-
설정 적용 후
Jira Automation
지금가지는 Github과 연동하여 Jira Task ID가 적힌 코드가 Pull Request로 올라오면 자동으로 Jira Task의 상태를 Review로 바꿔주고 코드가 병합되면 Close로 바꿔주는 설정만 해놓았었다.
최근에 아이디어가 떠올라 백엔드 인원이 담당자로 할당될 때 자동으로 백엔드에서 사용하는 라벨이 달리도록 Automation을 추가했다. 지금까지 하나하나 수동으로 할당해주었었는데 진작 해둘껄 그랬다.
이런식으로 Automation을 잘 활용해서 사용하면 손으로 해야하는 여러가지 번거로운 작업들을 자동화 할 수 있으니 잘 활용해봐야겠다.
Sonarqube Badges
얼마전에 사내 서버에서 소나큐브 서버를 올려놓고 활용중에 있다. 소나큐브에도 README.md에 적용시킬만한 뱃지 기능을 제공해주는데 기존에 적용한 뱃지보다 더 나은 정보를 제공해주는 것 같아서 변경했다.
![]()
그나저나 정리서비스의 테스트 코드를 제거하면서 커버리지가 너무 낮아져버렸다. 빨리 운영코드 제거해버리고 싶다.
기능테스트 시 데이터베이스 이슈
기능테스트와 Repository테스트 시 데이터베이스를 공유하는 상황이 발생하였다. PostgreSQL의 방언때문에 Repository테스트에서 인메모리 데이터베이스를 사용하지 않고 TestContainer를 이용하여 데이터베이스를 설정하고 테스트하고 있는데 이것 때문에 데이터베이스를 공유하는 상황이 발생하는 것이었다.
이 문제를 해결하기 위한 방법은 아래 3가지 정도로 생각해보았다.
- 데이터베이스 분리
- Repository 테스트 전 데이터 삭제
- 데이터 중복이 생기지 않게 테스트
1번이 가장 쉬운 방법이고 2번, 3번으로 갈수록 어려운 해결방법이다. 나의 선택은 쉬우면서 확실한 1번이다. 기능테스트 끼리야 어쩔 수 없는데 Repository 테스트는 단위테스트와 같이 격리된 환경에서 테스트키리 영향을 받지 않아야 다양한 테스트 케이스를 손쉽게 테스트할 수 있기 때문에 기능테스트와 데이터베이스를 격리 시키는 것이 중요하다고 생각했다.
로컬에서 적용하는 방법은 쉬웠다. 그냥 TestContainer를 이용하여 데이터베이스를 실행시킬 때 별도로 Container를 만들어서 실행시키면 되었기 때문이다.
@TestConfiguration
class FunctionalTestConfig {
@Profile("!ci")
@Bean
fun postgresqlTestContainer(): PostgreSQLContainer<Nothing> {
return PostgreSQLContainer<Nothing>("postgres:11")
.apply { withDatabaseName("test_database") }
.apply { withUsername("root") }
.apply { withPassword("password") }
.apply { start() }
}
@Profile("!ci")
@DependsOn("postgresqlTestContainer")
@Bean("jdbcUrl")
fun localJdbcUrl(postgresqlTestContainer: PostgreSQLContainer<Nothing>): String {
return postgresqlTestContainer.jdbcUrl
}
@Bean
fun dataSource(@Qualifier("jdbcUrl") jdbcUrl: String): DataSource {
return DataSourceBuilder.create()
.url(jdbcUrl)
.driverClassName("org.postgresql.Driver")
.username("root")
.password("password")
.build()
}
}
@TestConfiguration
class RepositoryTestConfig {
@Profile("!ci")
@Bean
fun postgresqlTestContainer(): PostgreSQLContainer<Nothing> {
return PostgreSQLContainer<Nothing>("postgres:11")
.apply { withDatabaseName("test_database") }
.apply { withUsername("root") }
.apply { withPassword("password") }
.apply { start() }
}
@Profile("!ci")
@DependsOn("postgresqlTestContainer")
@Bean("jdbcUrl")
fun localJdbcUrl(postgresqlTestContainer: PostgreSQLContainer<Nothing>): String {
return postgresqlTestContainer.jdbcUrl
}
@Bean
fun dataSource(@Qualifier("jdbcUrl") jdbcUrl: String): DataSource {
return DataSourceBuilder.create()
.url(jdbcUrl)
.driverClassName("org.postgresql.Driver")
.username("root")
.password("password")
.build()
}
}
CI에서 데이터베이스를 분리하는게 조금 까다로웠는데, CircleCI에서 PostgreSQL 이미지를 가지고와서 사용할 때 Port를 임의로 지정할 수 없었기 때문이다. 그래서 단순히 port를 다르게 해서 Container를 띄울 수 없는 상황이었다. 다행히 CircleCI에서 이러한 문제를 해결하는 방법으로 docker에 이름을 지정해주면 해당 이름을 host명으로 활용할 수 있는 방법을 제공해주었고 아래와 같이 설정하여 CI환경에서 데이터베이스를 두대 띄워서 사용하게 되었다.
- CircleCI 설정
# config.yml
test-executor:
docker:
- image: cimg/openjdk:17.0.4
- image: cimg/postgres:11.13
name: test_database_for_repository
environment:
POSTGRES_USER: root
POSTGRES_PASSWORD: password
POSTGRES_DB: test_database
- image: cimg/postgres:11.13
name: test_database_for_functional
environment:
POSTGRES_USER: root
POSTGRES_PASSWORD: password
POSTGRES_DB: test_database
- image: rmohr/activemq:5.15.9
- 기능 테스트 설정
@TestConfiguration
class FunctionalTestConfig {
@Profile("!ci")
@Bean
fun postgresqlTestContainer(): PostgreSQLContainer<Nothing> {
return PostgreSQLContainer<Nothing>("postgres:11")
.apply { withDatabaseName("test_database") }
.apply { withUsername("root") }
.apply { withPassword("password") }
.apply { start() }
}
@Profile("!ci")
@DependsOn("postgresqlTestContainer")
@Bean("jdbcUrl")
fun localJdbcUrl(postgresqlTestContainer: PostgreSQLContainer<Nothing>): String {
return postgresqlTestContainer.jdbcUrl
}
@Profile("ci")
@Bean("jdbcUrl")
fun ciJdbcUrl(): String {
return "jdbc:postgresql://test_database_for_functional:5432/test_database"
}
@Bean
fun dataSource(@Qualifier("jdbcUrl") jdbcUrl: String): DataSource {
return DataSourceBuilder.create()
.url(jdbcUrl)
.driverClassName("org.postgresql.Driver")
.username("root")
.password("password")
.build()
}
}
- Repository 테스트 설정
@TestConfiguration
class RepositoryTestConfig {
@Profile("!ci")
@Bean
fun postgresqlTestContainer(): PostgreSQLContainer<Nothing> {
return PostgreSQLContainer<Nothing>("postgres:11")
.apply { withDatabaseName("test_database") }
.apply { withUsername("root") }
.apply { withPassword("password") }
.apply { start() }
}
@Profile("!ci")
@DependsOn("postgresqlTestContainer")
@Bean("jdbcUrl")
fun localJdbcUrl(postgresqlTestContainer: PostgreSQLContainer<Nothing>): String {
return postgresqlTestContainer.jdbcUrl
}
@Profile("ci")
@Bean("jdbcUrl")
fun ciJdbcUrl(): String {
return "jdbc:postgresql://test_database_for_repository:5432/test_database"
}
@Bean
fun dataSource(@Qualifier("jdbcUrl") jdbcUrl: String): DataSource {
return DataSourceBuilder.create()
.url(jdbcUrl)
.driverClassName("org.postgresql.Driver")
.username("root")
.password("password")
.build()
}
}
Mockk relexed 글로벌 설정
단위테스트에서 Mocking을 위해 Mockk을 사용하고 있다. 테스트할 때 관심대상이 아님에도 Mocking을 해주는게 불편해서 아래와 같이 relexed 설정을 자주 활용하는데 매번 이러한 설정을 해주는게 불편하다는 생각이 들었다.
val client = mockk(relaxed = true)
한편 왜 relexed가 기본값이 true가 아닐까 하는 궁금증이 생겼다. Stackoverflow에서 내가 가진 의문에 대한 답을 찾을 수 있었는데, 기본값으로 true를 하지 않은 이유는 개발자가 의도적으로 Mocking하지 않는 함수를 기본값으로 반환한다면 테스트에서 예측할 수 없는 동작이 실행될 수 있기 때문이라고 한다. 즉, 잘못된 테스트를 하지 않도록 방지하기 위함이라는 것을 알 수 있다.
하지만 나는 Query 함수에 대해서는 위 의견에 동의하지만 Command 함수에서는 어차피 verify에서 검증을 하기 때문에 기본값으로 실행되어도 우려하는 문제는 발생하지 않는다고 생각한다. Mockk에서는 relaxedUnitFun이라는 설정을 통해 반환값이 없는 함수에 대해서 Mocking을 명시적으로 해주지 않아도 기본값으로 실행되게끔 해주는 기능을 제공해주고 있다. 그래서 relaxedUnitFun를 글로벌로 설정한다면 굳이 매 함수마다 relaxedUnitFun을 설정해주지 않아도 되니 편리할 것이라 생각했다.
글로벌로 relaxedUnitFun를 설정해주는 방법은 아래와 같다. 테스트의 resources 디렉터리 안에 아래와 같이 파일을 생성해주면된다.
# resources/io/mockk/settings.properties
relaxUnitFun=true
단위 테스트 SUT 설정 방법 변경 제안
기본의 단위테스트 설정방법 보다 나은 방법이 있어서 단위 테스트 SUT(System under test) 설정 방법을 소개하고자 한다.
아래 코드의 문제점이 무엇일까?
class AdminAnnouncementMessageFacadeTest : FunSpec() {
private val adminAnnouncementMessageHistoryService: AdminAnnouncementMessageHistoryService = mockk()
private val orderableVendorService: OrderableVendorService = mockk()
private val storeService: StoreService = mockk()
private val chatClient: ChatClient = mockk()
private val adminAnnouncementMessageFacade: AdminAnnouncementMessageFacade = AdminAnnouncementMessageFacade(
adminAnnouncementMessageHistoryService,
orderableVendorService,
storeService,
chatClient,
)
//...테스트
}
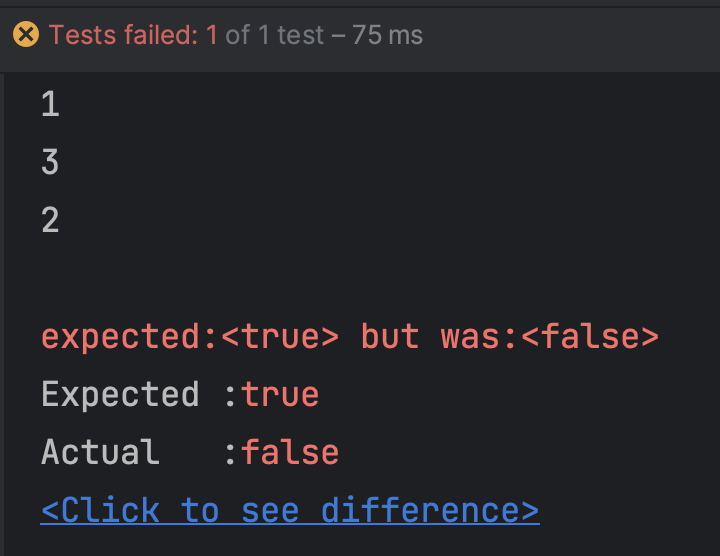
하나의 테스트 케이스가 다른 테스트 케이스에 영향을 미친다는 것이다. 아래 코드와 같이 test2는 every 설정을 하지 않았음에도 값이 반환됨을 볼 수 있다.
val histories = AdminAnnouncementMessageHistoryFactory().produceMany().take(3).toList()
test("test") {
every { adminAnnouncementMessageHistoryService.getHistories(Pageable.unpaged()) } returns PageImpl(histories)
val actual = adminAnnouncementMessageHistoryService.getHistories(Pageable.unpaged())
println(actual.totalElements) // 3
}
test("test2") {
val actual = adminAnnouncementMessageHistoryService.getHistories(Pageable.unpaged())
println(actual.totalElements) // 3
}
물론 공통설정을 목적으로 의도적으로 위와 같이 작성할 순 있다. 하지만 그렇게 하고 싶다면 beforeEach에서 정의를 하는게 맞다고 생각한다.
그래서 위 문제를 해결하기 위해 아래와 같이 SUT를 정의했었었다.
class AdminAnnouncementMessageFacadeTest : FunSpec() {
private lateinit var adminAnnouncementMessageHistoryService: AdminAnnouncementMessageHistoryService
private lateinit var orderableVendorService: OrderableVendorService
private lateinit var storeService: StoreService
private lateinit var chatClient: ChatClient
private lateinit var adminAnnouncementMessageFacade: AdminAnnouncementMessageFacade
override suspend fun beforeEach(testCase: TestCase) {
adminAnnouncementMessageHistoryService = mockk()
orderableVendorService = mockk()
storeService = mockk()
storeService = mockk()
chatClient = mockk()
adminAnnouncementMessageFacade = AdminAnnouncementMessageFacade(
adminAnnouncementMessageHistoryService,
orderableVendorService,
storeService,
chatClient,
)
}
}
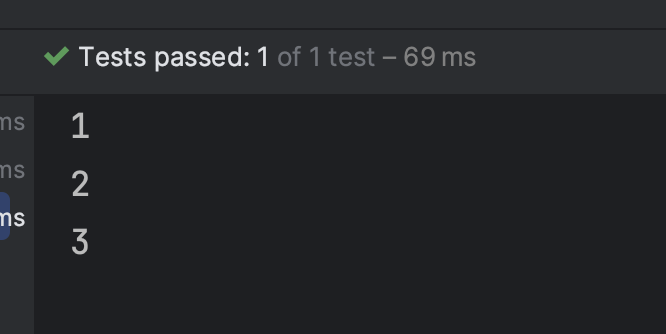
이렇게 하면 매 테스트마다 mocking을 초기화 하기 때문에 위에서 정의한 테스트 코드는 실패하게 된다.
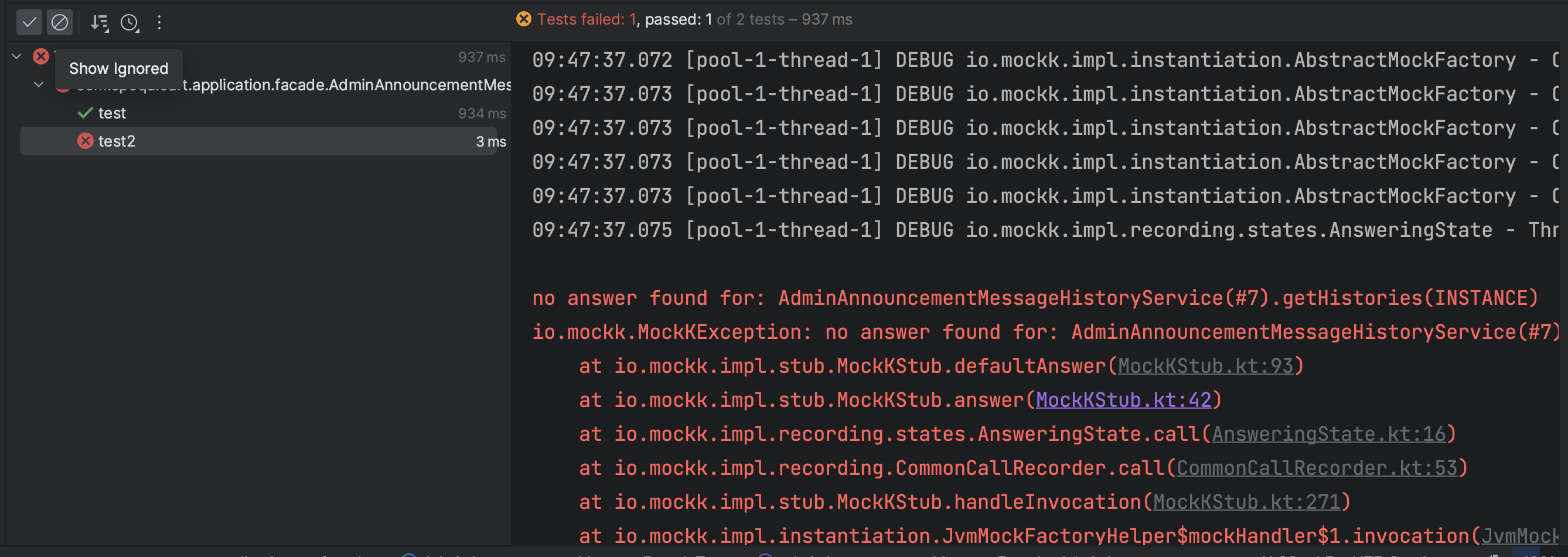
val histories = AdminAnnouncementMessageHistoryFactory().produceMany().take(3).toList()
test("test") {
every { adminAnnouncementMessageHistoryService.getHistories(Pageable.unpaged()) } returns PageImpl(histories)
val actual = adminAnnouncementMessageHistoryService.getHistories(Pageable.unpaged())
println(actual.totalElements) // 3
}
test("test2") {
val actual = adminAnnouncementMessageHistoryService.getHistories(Pageable.unpaged())
println(actual.totalElements) // error
}
no answer found for: AdminAnnouncementMessageHistoryService(#7).getHistories(INSTANCE) 즉, mocking이 되지 않았으니 응답값을 알 수 없는 것이다.
하지만 위 방법에는 몇가지 문제점이 있다.
-
lateinit var를 사용한다. SUT는 한번 정의하면 재할당할 필요가 없다. 그럼에도 불구하고 var를 사용하기 때문에 아래와 같이 테스트 코드에서 재할당할 가능성이 존재하게 된다. 물론 누군가 테스트를 망가뜨릴 목적으로 하지 않는한 거의 발생하지 않겠지만 lateinit var는 좋지 못한 패턴임이 분명하다.
-
매 테스트 코드마다 객체를 새로 생성한다. 단위 테스트를 수행할 SUT 객체는 그렇게 무겁지는 않다. 하지만 프로젝트에 단위테스트를 작성하다보면 점점 코드가 엄청 많아지게된다. 매 단위테스트에서 객체를 테스트 케이스마다 재생성한다면 분명 메모리 사용량이 그렇지 않은 코드보다는 많아질 것이다.
위와같은 이유로 아래와 같이 단위테스트를 위한 SUT 정의 방법을 변경해 보았다.
class AdminAnnouncementMessageFacadeTest : FunSpec() {
private val adminAnnouncementMessageHistoryService: AdminAnnouncementMessageHistoryService = mockk()
private val orderableVendorService: OrderableVendorService = mockk()
private val storeService: StoreService = mockk()
private val chatClient: ChatClient = mockk()
private val adminAnnouncementMessageFacade: AdminAnnouncementMessageFacade = AdminAnnouncementMessageFacade(
adminAnnouncementMessageHistoryService,
orderableVendorService,
storeService,
chatClient,
)
override suspend fun beforeEach(testCase: TestCase) {
clearAllMocks()
}
init {
val histories = AdminAnnouncementMessageHistoryFactory().produceMany().take(3).toList()
test("test") {
every { adminAnnouncementMessageHistoryService.getHistories(Pageable.unpaged()) } returns PageImpl(histories)
val actual = adminAnnouncementMessageHistoryService.getHistories(Pageable.unpaged())
println(actual.totalElements) // 3
}
test("test1") {
val actual = adminAnnouncementMessageHistoryService.getHistories(Pageable.unpaged())
println(actual.totalElements) // error
}
}
}
프로그래밍에서 인지편향
개발자 편향과 관련해서 글을 찾다가 발견한 글이 있어 기록해 둔다.
프로그래밍에서 인지편향이라는 글인데 요점만 정리해서 적으면 아래와 같다.
- 과도한 가치 폄하: 나중의 더 큰 보수 대신에 지금 당장의 이익을 우선시 하는 것.
- 이케아 효과: 문제에 대한 자신의 해결책은 과대 평가하는 반면, 다른 솔루션을 과소 평가하는 것.
- 어설픈 최적화: 필요한 것을 이해하기도 전에 최적화하는 것.
- 계획 오류: 작업을 완료하는 데 필요한 시간을 낙관적으로 예상하는 것
- 최신 편향: 과거에 일어난 일보다 최근의 사건에 높은 가치를 두는 것. 최신 경험을 더 가치있다고 생각하는 것.
Unleash
최근 관리자의 공사 중 페이지를 표현하기 위한 피쳐 토글 기능을 알아보다가 발견한 오픈소스가 바로 Unleash이다.
사실 해당 라이브러리는 맘시터 기술블로그를 통해서 알게되었다.
UI콘솔도 제공해주고 기능이 나쁘지 않은거 같아서 시간이되면 관리자에 POC해봐야겠다.
기능 테스트에서의 enable_lazy_load_no_trans
기능테스트로 전환하면서 테스트를 위한 데이서 생성시 Facade 함수들을 이용하는 Fixture를 만들어서 사용하고 있는데 이때 Transaction 밖에서 조회를 하다보니 LateInitializationError를 겪게되는 상황이 발생했다.
Transaction 밖에서 lazy loading을 사용할 방법을 찾다가 간단하게 아래와 같이 설정을 하면 LateInitializationError가 발생하지 않도록 조치할 수 있다. 다만, 안티 패턴이니 운영코드에서는 사용하지 말자.
spring.jpa.properties.hibernate.enable_lazy_load_no_trans=true
하지만 해당 설정을 결국 적용하지 않기로 결정했다. 왜냐하면 기능테스트를 하는 이유가 통합테스트에서는 발견할 수 없었던 Transaction 밖에서의 이슈를 감지하기 위함인데 이렇게 설정해버리면 실제 운영코드에서 발생하는 LateInitializationError를 발견할 수 없기 때문이다.
DGS CustomGraphQLClient 이슈
테스트를 위해서 CustomGraphQLClient를 사용하고 있다.
Webflux를 사용하고 있지 않은 우리 프로젝트 특성상 테스트를 위해 가장 합리적인 선택이 CustomGraphQLClient이었는데 아래와 같이 테스트 코드를 작성하면 오류가 발생하는 이슈가 있다.
val client = // ... 클라이언트 생성
val input = CreateOrderSheetInput(
orderableVendorId = orderableVendor.id!!,
requestedDeliveryDate = LocalDate.of(2023, 1, 1),
additionalRequests = "요청 사항",
products = listOf(
CreateOrderSheetProductInput(
orderableVendorProductId = product.id,
count = 10.toDouble(),
),
),
)
val variables = mapOf("input" to input)
// When
val actual = client.executeQuery(mutation, variables)
.extractValueAsObject("createOrderSheet", typeRef<CreateOrderSheet>())
Java 8 date/time type `java.time.LocalDate` not supported by default: add Module "com.fasterxml.jackson.datatype:jackson-datatype-jsr310" to enable handling (through reference chain: com.netflix.graphql.dgs.client.Request["variables"]->java.util.Collections$SingletonMap["input"]->com.spoqa.cart.generated.types.CreateOrderSheetInput["requestedDeliveryDate"])
com.fasterxml.jackson.databind.exc.InvalidDefinitionException: Java 8 date/time type `java.time.LocalDate` not supported by default: add Module "com.fasterxml.jackson.datatype:jackson-datatype-jsr310" to enable handling (through reference chain: com.netflix.graphql.dgs.client.Request["variables"]->java.util.Collections$SingletonMap["input"]->com.spoqa.cart.generated.types.CreateOrderSheetInput["requestedDeliveryDate"])
at com.fasterxml.jackson.databind.exc.InvalidDefinitionException.from(InvalidDefinitionException.java:77)
at com.fasterxml.jackson.databind.SerializerProvider.reportBadDefinition(SerializerProvider.java:1300)
at com.fasterxml.jackson.databind.ser.impl.UnsupportedTypeSerializer.serialize(UnsupportedTypeSerializer.java:35)
at com.fasterxml.jackson.databind.ser.BeanPropertyWriter.serializeAsField(BeanPropertyWriter.java:728)
at com.fasterxml.jackson.databind.ser.std.BeanSerializerBase.serializeFields(BeanSerializerBase.java:774)
at com.fasterxml.jackson.databind.ser.BeanSerializer.serialize(BeanSerializer.java:178)
... 생략
원인을 확인해보니 CustomGraphQLClient에서 input값 중 시간값을 Serialize 하지 못해 발생하는 것이었다. DGS의 문서를 보면 Custom Object Mapper를 설정할 수 있는 방법이 나온다. 그래서 아래와 같이 설정해 보았다.
@Bean
fun dgsObjectMapper(): ObjectMapper {
return ObjectMapper().apply {
registerModule(JavaTimeModule())
}
}
하지만 안타깝게도 해당 설정도 제대로 동작하지 않았다. 원인은 CustomGraphQLClient의 구현코드에 있었다. 구현코드를 보면 아래와 같이 구현되어있는 것을 볼 수 있다.
class CustomGraphQLClient(private val url: String, private val requestExecutor: RequestExecutor) : GraphQLClient {
//...
override fun executeQuery(query: String, variables: Map<String, Any>, operationName: String?): GraphQLResponse {
val serializedRequest = GraphQLClients.objectMapper.writeValueAsString(
Request(
query,
variables,
operationName
)
)
val response = requestExecutor.execute(url, GraphQLClients.defaultHeaders, serializedRequest)
return GraphQLClients.handleResponse(response, serializedRequest, url)
}
}
internal object GraphQLClients {
internal val objectMapper: ObjectMapper =
if (ClassUtils.isPresent("com.fasterxml.jackson.module.kotlin.KotlinModule\$Builder", this::class.java.classLoader)) {
ObjectMapper().registerModule(KotlinModule.Builder().nullIsSameAsDefault(true).build())
} else ObjectMapper().registerKotlinModule()
// ...생략
}
즉, 설정값을 통해 ObjectMapper를 빈으로 주입받는 것이 아닌 인터페이스 내부에서 직접 생성자로 생성하는 것이기 때문에 앞서 말한 Custom Object Mapper 설정을 할 수 없는 것이다.
결국 어쩔 수 없이 아래와 같이 CustomGraphQLClient를 직접 구현해주는 방식으로 문제를 해결했다.
class CustomGraphQLClient(
private val url: String,
private val objectMapper: ObjectMapper,
private val requestExecutor: RequestExecutor,
) : GraphQLClient {
override fun executeQuery(query: String): GraphQLResponse {
return executeQuery(query, emptyMap(), null)
}
override fun executeQuery(query: String, variables: Map<String, Any>): GraphQLResponse {
return executeQuery(query, variables, null)
}
override fun executeQuery(query: String, variables: Map<String, Any>, operationName: String?): GraphQLResponse {
val serializedRequest = objectMapper.writeValueAsString(
Request(
query,
variables,
operationName,
),
)
val headers = HttpHeaders.readOnlyHttpHeaders(
HttpHeaders().apply {
accept = listOf(MediaType.APPLICATION_JSON)
contentType = MediaType.APPLICATION_JSON
},
)
val response = requestExecutor.execute(url, headers, serializedRequest)
return handleResponse(response, serializedRequest, url)
}
private fun handleResponse(response: HttpResponse, requestBody: String, url: String): GraphQLResponse {
val (statusCode, body) = response
val headers = response.headers
if (statusCode !in 200..299) {
throw GraphQLClientException(statusCode, url, body ?: "", requestBody)
}
return GraphQLResponse(body ?: "", headers)
}
}
data class Request(val query: String, val variables: Map<String, Any>, val operationName: String?)
ObjectMapper를 주입받는 좋은 방법이 있는지는 아직 잘 모르겠다. 그래서 이슈로 개선요청을 한 상태이다.
https://github.com/Netflix/dgs-framework/issues/1461
답변 받은 내용으로보아 일단 TimeModule을 먼저 추가해주고 주입 받는 방법을 모색한다고 한다.
TransactionalEventListener 이슈
TransactionalEventListener를 쓰면 TX가 끝나야 이벤트가 실행된다. 가끔 필요한 상황이 생기면 쓸만하지만….숨은 로직을 만드는 결과를 초래하게되고 코드순서대로 동작하지 않기 때문에 디버깅이 어렵다.
아래에 내가 겪었던 사례를 적어본다.
이벤트를 수신하여 실행되는 채팅방 초대 함수가 실행되는 숨은 로직이 있었다. 해당 코드는 Transaction이 끝나고 동작해야 정상적으로 동작한다. 이유는 아래 코드 때문이다.
@Transactional
fun createAccount(data: CreateOrderableVendorAccountFacadeData): OrderableVendorAccount {
val orderableVendor = 거래처 조회
val createOrderableVendorAccountData = 데이터 생성
// 1
val createdAccount = orderableVendorAccountService.createAccount(createOrderableVendorAccountData)
// 2
val response = chatClient.createOrderableVendorAccountChatUser(createdAccount)
// 3
orderableVendorAccountService.updateSendbirdUserId(
orderableVendorAccountId = createdAccount.id,
newSendbirdId = response.userId.toString(),
)
return createdAccount
}
코드에 대한 설명하면 아래와 같다.
- 유통사 계정을 생성한다.
- 샌드버드 사용자를 생성한다.
- 샌드버드 사용자 ID를 생성한 유통사 계정에 업데이트 한다.
문제는 1번 코드이다. 채팅방 초대 함수는 1번에서 발행한 유통사 계정 생성 이벤트를 받아 실행된다. 다만 Listener가 TransactionalEventListener이기 때문에 Facade의 로직중 3번이 모두 실행되고 난 후 실행된다. 즉, 1번이 실행된 후 실행되는게 아니라 3번이 실행된 후 동기적으로 실행되는 것이다.
채팅방 초대 함수 코드 내부에 보면 SendbirdID를 이용하여 채팅방에 초대를 하는 로직이 있다. TransactionalEventListener를 사용하면 3번이 실행된 후 해당 코드가 실행되기 때문에 문제가 없지만 EventListener로 변경하면 SendbirdID가 null이기 때문에 널포인터 에러가 발생한다.
그럼 위 facade.createAccount함수를 어떻게 바꾸면 좋을까?
orderableVendorAccountService.createAccount의 매개변수에 sendbirdId를 가지고 오는 것을 람다로 넘기고 facade에서 chatClient.createOrderableVendorAccountChatUser(createdAccount)를 람다에 넣는 식으로 하면 의존성을 역전시킬 수 있다.
@Transactional
fun createAccount(data: CreateOrderableVendorAccountFacadeData): OrderableVendorAccount {
val orderableVendor = 거래처 조회
val createOrderableVendorAccountData = 데이터 생성
return orderableVendorAccountService.createAccount(createOrderableVendorAccountData) {
chatClient.createOrderableVendorAccountChatUser(createdAccount).sendBirdId
}
}
그리고 orderableVendorAccountService.updateSendbirdUserId를 orderableVendorAccountService.createAccount에 넣는다면 더이상 TransactionalEventListener를 사용하지 않고도 이벤트를 처리할 수 있게 된다.
회사 코드를 그대로 들거온거라 자세하게는 못적지만 의존성을 역전시키는 방법에 대한 글을 나중에 써봐야겠다.
Mockserver Log Level 바꾸는 법
Mockserver를 기본설정으로 사용하면 Mocking과 관련한 로그가 너무 많이 적혀서 테스트 시 디버깅이 어려울 수 있다. 그래서 아래와 같이 로그 레벨을 조정하여 원하는 로그만 볼 수 있다.
val configuration = Configuration.configuration().logLevel(Level.WARN)
mockServer = ClientAndServer.startClientAndServer(configuration, listOf(SENDBIRD_API_PORT, SLACK_API_PORT))