
Fluent Python

Introduction
현재 회사에서 Python을 주 언어로 사용하고 있다. 지금까지 나는 Java, Kotlin, Javascript 언어를 주로 사용해왔었고 Python은 코딩 튜터로 활동할때 조금 사용해 보았지만 제대로 안다고 말하기 어려웠다. 그래서 Python에 대해 좀더 깊이 있게 알아보기 위해 이 책을 읽게 되었다.
책의 구성
책의 내용은 개념의 설명과 함께 코드 예제를 통해 이해를 돕는 형식으로 구성이 되어있다. 직접 코드를 작성해가면서 책을 읽어나간다면 훨씸 더 도움이 되었으리라 생각한다. 그리고 본내용의 설명을 마친 후 요약과 읽을거리, 뒷이야기를 소개해주는 부분도 아주 좋았다.
들어가며
이 장에서는 Python의 특별메소드에 대한 소개를 해주고 있다. 특별메소드는 파이썬에서 아주 중요한 역할을 하고 있으며 이 특별메소드에 대해서 알게되면서 다른 객체지향 언어와 달리 파이썬이 왜 len(collection)과 같은 방식을 사용하는지 이해할 수 있게 되었다.
기억에 남는 특별메소드는 아래와 같다.
__repr____str____len____getitem____init____getattr____iter____next____eq__
이외에도 수많은 특별메소드들이 있으며 다 외우기는 힘들겠지만 알아두면 필요한 곳에 적절히 사용할 수 있을 것이다.
데이터 구조체
이번 장에서는 많은 내용을 다룬다. 솔직히 모두 이해하긴 어려웠으며 실무에서 사용하였거나 사용해봄직한 내용들 위주로 적어보았다.
지능형 리스트
나는 kotlin이나 javascript에서는 배열을 다룰때 filter나 map을 이용한다.
파이썬에서도 아래와 같이 filter와 map 함수를 이용하여 배열을 다루어 왔었다. (처음엔 filter와 map이 collection.filter, collection.map과 같이 표현되지 않는지 의구심을 가졋지만 특별메서드에 대해서 알게되면서 왜 이렇게 되었는지 어느정도 이해하게 되었다. 하지만 여전히 맘에 드는 스타일은 아니다.)
list(filter(lambda c: c > 127, map(ord, symbols)))
하지만 지능형 리스트를 배우고 나서는 더이상 위와 같이 작성하지 않고 있다.
[ord(s) for s in symbols if ord(s) > 127]
제너레이터 표현식
제너레이터 표현식은 지능형 리스트와 유사하지만 배열을 통째로 생성하지 않고 iterator protocol을 이용해서 항목을 하나씩 나중에 생성하기 때문에 메모리 효율성을 높일 수 있다.
(ord(symbol) for symbol in symbols)
튜플 언패킹
언페킹은 DTO와 같은 데이터 구조체를 다룰때 가독성을 높이거나 코드의 양을 줄이는데 유용하게 사용될 수 있다. 그래서 이 방법을 알고 난 후 DTO를 다룰때 되도록이면 언패킹을 이용한다.
@dataclasses.dataclass(frozen=True)
class Foo:
a: str
b: int
def __iter__(self):
return iter((
self.a,
self.b,
))
def foo(data: Foo):
a, b = data
지능형 딕셔너리
지능형 리스트와 마찬가지로 지능형 딕셔너리도 높은 가독성 코드를 제공한다.
{country: code for code, country in DIAL_CODES}
객체로서의 함수
javascript와 유사하게 python도 함수는 일급 객체이다. 그래서 함수를 객체처럼 다룰 수 있으며, 함수를 인수로 받거나 결과로 반환할 수 있는 고위 함수를 사용할 수 있다.
lambda키워드를 이용해서 익명함수를 생성할 수도 있다. (개인적으로는 가독성이 썩 좋아보이는 문법은 아니다.)
functools.partial
functools.partial로 인수를 고정하여 함수를 부분적으로 실행할 수 있다. 해당 함수는 python의 라이브러리 곳곳에서 사용되고 있는데 이 부분을 읽지 않았다면 이해하는데 많은 시간을 썼을 듯하다. 아래는 graphene 라이브러리의 일부이다.
@classmethod
def connection_resolver(cls, resolver, connection_type, model, root, info, **args):
resolved = resolver(root, info, **args)
on_resolve = partial(cls.resolve_connection, connection_type, model, info, args)
if is_thenable(resolved):
return Promise.resolve(resolved).then(on_resolve)
return on_resolve(resolved)
데커레이터
Python에서 데커레이터는 데커레이터 패턴의 데커레이터와는 조금 다르다고 한다. 여기서 데커레이터는 다른 함수를 인수로 받는 콜러블이다.
데커레이터를 이용하면 클로저를 사용할 수 있는데 이러한 특징을 이용해서 현재 실무에서 Spring의 Component과 유사하게 서비스 객체들의 생명주기를 관리할 수 있는 데커레이터를 만들어서 사용중이다.
def component(func: Callable) -> Callable:
"""Component의 라이프사이클을 관리하기 위한 Decorator입니다.
해당 Decorator는 Component객체의 생성을 캐시하여 앱의 메모리 사용을 최적화 합니다.
`components`는 자유변수이며 Component들을 캐싱하여 담아두는 용도로 사용됩니다.
사용예시:
# 샘플 서비스
@component
def foo_service() -> FooService:
return FooService()
# 샘플 클라이언트
def foo_mutate():
foo_service().foo_method()
"""
components = {}
@functools.wraps(func)
def wrapper(*args, **kwargs):
name = func.__name__
cached_component = components.get(name)
if cached_component:
return cached_component
components[name] = func(*args, **kwargs)
return func(*args, **kwargs)
return wrapper
객체지향 상용구
이 장의 내용중 기억 나는 문구는 변수는 상자가 아니다이다. 흔히 처음 개발을 접하는 사람들에게 변수를 설명할 때 특정 값을 상자에 담는 것 처럼 표현하곤 한다. 하지만 변수는 값을 담는 그릇이 아니라 값에 붙이는 라벨과 같은 의미로 이해하면 좋을 것이다.
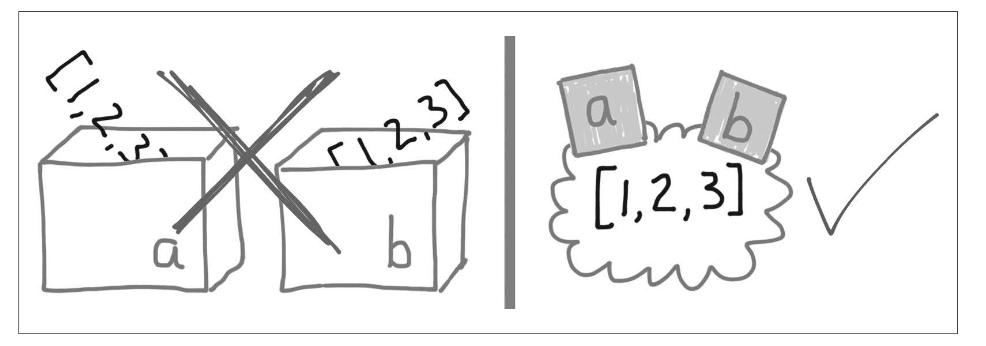
기본값 사용의 위험성
책을 읽으면서 깜짝 놀랐던 부분이 바로 가변형을 매개변수 기본값으로 사용할때 발생할 수 있는 문제점이었다.
class Queue:
def __init__(self, queue=[]):
self.queue = queue
def pick(self, data):
self.queue.append(data)
def drop(self, data):
self.queue.remove(data)
>>> q1 = Queue([1,2,3,4,5])
>>> q1.queue
[1, 2, 3, 4, 5]
>>> q1.pick(6)
>>> q1.queue
[1, 2, 3, 4, 5, 6]
>>> q1.drop(4)
>>> q1.queue
[1, 2, 3, 5, 6]
>>> q2 = Queue()
>>> q2.pick(1)
>>> q2.queue
[1]
>>> q3 = Queue()
>>> q3.queue
[1]
>>> q3.pick(2)
>>> q2.queue
[1, 2]
>>> q3.queue
[1, 2]
이런 문제점이 생기지 않도록 하기 위해서는 아래와 같이 기본값을 None을 받은 후 본문에서 새롭게 할당해서 넣어주면 해결할 수 있다.
class Queue:
def __init__(self, queue=None):
if queue is None:
self.queue = []
else:
self.queue = queue
def pick(self, data):
self.queue.append(data)
def drop(self, data):
self.queue.remove(data)
>>> q1 = Queue()
>>> q1.pick(1)
>>> q1.queue
[1]
>>> q2 = Queue()
>>> q2.queue
[]
>>> q2.pick(2)
>>> q1.queue
[1]
>>> q2.queue
[2]
덕 타이핑
단지 객체에 필요한 메서드를 구현하면 기대한 대로 동작한다
나는 주로 정적언어를 사용해 오다보니 덕타이핑을 처음 접했을 때 장점보다는 단점이 훨씬 더 많이 느껴졌다. 내가 덕타이핑에 대해 제대로 이해하지 못했을 수도 있다. 지금까지 내가 이해한 바로는 그렇다.
장점
내가 느낀 장점으로는 첫번째 편리함이다. 인터페이스를 상속하지 않고도 해당 함수를 구현하기만 하면 해당 구현체는 특정 인터페이스의 구현체와 같이 동작할 수 있다. 어찌보면 동적언어의 특징에 아주 잘 맞는 방식이라 생각한다. 타입이 없는데 굳이 인터페이스의 상속을 표현해 줄 필요가 있을까? 클라이언트 코드에서 해당 함수를 호출하기만 하면되고 함수가 구현되어 있다면 원하는 대로 동작할 것이다.
두번째 인터페이스의 모든 동작을 구현하지 않고 필요한 함수만 구현하면 된다. 정적 언어에서 인터페이스를 구현한다면 인터페이스에 정의된 모든 함수를 구현해야 한다. 심지어 사용하지 않음에도 말이다. (이는 ISP(인터페이스 분리원칙)에 위배되는데 논지에 벗어날 수 있으므로 길게 설명하지는 않겠다.) 하지만 덕 타이핑은 필요한 함수만 구현해도 문제 없이 동작한다.
단점
내가 느낀 단점으로는 첫번째 명시적이지 않다 이다. 덕 타이핑으로 인터페이스의 행위를 구현하면 구현체는 해당 인터페이스의 행위를 구현하고 있음을 알 수 있는 방법이 마땅히 없다. 그냥 동작하기 때문에 해당 인터페이스를 구현하였을 것이라 가정할 뿐이다. 그럼 개발자는 인터페이스에 대한 정보를 어떻게 얻을 수 있을까? 바로 문서(주석)를 통해서이다. 클린코드에서도 언급되지만 문서(주석)은 코드와 생명주기를 함께하지 못한다.
두번째 단점은 높은 오류가능성이다. 컴파일 타임에 명세가 충족되었는지 알기 어렵기 때문에 잘못된 자료형이 넘어가고 잘못된 구현에 의한 실행이 의도치 않게 동작한다면 유지보수 관점에서는 지옥과 다름없다. 시간이 지날수록 코드에서는 악취가 진동할 것이고 아무도 그 코드를 신뢰할 수 없을 것이다. (물론 이는 테스트코드를 통해 보완할 수 있다.)
접근제어자
정적언어를 사용해 왔다보니 python에서 접근제어자가 없다는 부분이 놀라웠다. 엄밀히 따지면 _를 이용해서 표현을 할 수는 있다. _는 protected를 __는 private를 의미한다. 하지만 클라이언트에서 접근할 수 있다. 물리적으로는 막지 못한다.
제어 흐름
이 장에서는 Python에서 사용하는 제너레이터를 좀더 심도있게 배웠다. 솔직히 제대로 이해하고 사용하기엔 아직 내 이해도가 부족해 보이긴 하다.
yield
yield와 yield from 키워드의 사용예제를 볼 수 있게 되었고 적어도 해당 키워드를 언제 무슨 용도로 사용하는지 정도는 이해할 수 있게 되었다.
코루틴
코루틴은 경량쓰레드를 이용하여 효율적인 동시성 프로그래밍을 할 수 있도록 도와준다. 마치 멀티 태스킹과 비슷한 느낌을 준다.
이 책에서 yield 키워드를 소개한 이유는 아마 코루틴을 알려주기 위해서가 아닐까 생각된다. 또 코루틴을 기동하기 위한 기반 코드를 위해 데커레이터가 활용되는 코드도 소개해 준다.
이 장에서 기억에 남는 인용문이 있어 적어본다.
동시성: 컴퓨터 과학에서 가장 어려운 주제 중 하나다(피하는 것이 상책이다).
asyncio를 이용한 동시성
예제를 통해서 Thread 기반 코드를 코루틴 기반으로 변경하는 방법을 소개해주는데, 직접 타이핑해보며 따라해보면 글로 읽을 때보다 훨씬 더 와 닿을 것 같다.
메타프로그래밍
동적속성
개인적으로 Python에서 제공해주는 기능중 마음에 드는 부분이 동적 속성을 제공하는 것이다. 코드를 간결하게 작성할 수 있게 도와줄 뿐만 아니라 사용방법도 어렵지 않기 때문이다. 동적 속성을 이용하면 함수를 마치 속성처럼 사용할 수 있어서 이점도 참 마음에 든다.
다만 동적속성을 사용할때 상속 등으로 인한 속성 전파나 오버라이딩에 신경을 잘 써야한다.
속성 디스크립터
속성 디스크립터를 배우고 나니 SQL Alchemy와 같은 ORM도구가 Entity 객체를 이용해 어떻게 데이터베이스 레코드를 매핑하는지 가볍게나마 이해할 수 있게 되었다.
클래스 메타프로그래밍
메타프로그래밍은 참 매력적이다. 이 책에서는 나와 같이 매력을 느끼는 개발자들에게 아래와 같은 조언을 해준다.
메타클래스는 99%의 사용자가 신경 써야 하는 것보다 훨씬 더 깊이 있는 마술이다
Wrap up
이 책을 읽고 Python의 전문가(?)는 되지 못하겠지만 이 책을 읽지 않았더라면 몰랐을 내용들을 많이 알 수 있게 되었고, 파이썬 스러움이 뭔지 조금은 알 수 있게 되었다. 뿐만아니라 개발 일반적인 조언도 많이 얻을 수 있어서 파이썬을 언어로 개발하는 개발자라면 한번쯤은 읽어보면 좋을 것 같다.