
도메인 주도 개발 전환 이야기
Intro
이 글은 현재 내가 몸담은 스포카의 도도카트 서비스에서 도메인을 정의하고 그것에 맞게 백엔드의 구조를 개선해 가는 과정을 적은 이야기이다. 도메인 주도 개발 전환 이야기라는 장황한 제목을 적긴 했지만 사실 현재 만들어져있는 도도카트의 백엔드 코드를 도메인에 맞게 재 구조화하고 리펙토링하는 과정을 적어볼 것이다. 사실 도메인 주도 라는 말보단 도메인 지향이라는 말이 좀 더 어울릴 것 같지만, 사람들에게는 도메인 주도라는 말이 좀 더 친숙할 테니 그냥 쓰려고 한다 ^^;;
이야기를 시작하기 전에 이해를 도우려고 현재 백엔드 서버의 스팩을 먼저 소개하자면 서버는 Flask를 기반으로 ORM으로 SQL Alchemy를, 그리고 Graphql 라이브러리로 Graphene을 사용하고 있다. 본문을 읽을 때 참고 하면 좋을 것 같다. 이제 본격적으로 이야기를 시작해 보자.
왜 시작하게 되었나?
도도카트 팀은 팀 아래에 앱 스쿼드와 백오피스 스쿼드로 나누어져 있고 앱 스쿼드에 기획자, 디자이너, 앱 개발자, 웹 개발자, 백엔드 개발자가 백오피스 스쿼드에 기획자, 디자이너, 웹 개발자, 백엔드 개발자로 구성되어 있었다. 의아했던 점 중 하나가 백엔드 개발자가 하나의 서버로 이루어져 있음에도 불구하고 앱스쿼드와 백오피스 스쿼드로 나누어져 있었다는 것이었다. 앞에서 말한 팀으로 구성되어 있으면 특정 도메인의 요구사항이 생겼을 때 기능에 대한 충돌뿐만 아니라 같은 공간의 코드를 작업할 가능성이 높으므로 코드 충돌이 발생하는 등의 문제점이 생기지 않을까 하는 생각이 들었다.
시간이 흘러 코드를 보니 위의 우려에도 왜 큰 불편함이 없었는지 알 수 있었는데, 하나의 테이블을 나타내는 Entity를 중심으로 로직의 대부분 GraphQL의 Resovler에 모두 작성되어 있었다. 그러다 보니 앱에서 필요한 API와 백오피스에서 필요한 API를 따로 만들면서 작업을 할 수 있었고 큰 기능 충돌이나 코드들의 충돌이 발생하지 않았던 것이다. 물론 Entity 작업 시에는 서로 영향을 끼치겠지만, 그 빈도가 크진 않았다.
이러한 구조는 초반에 빠르게 제품을 만들어 시장성을 검증하기 위한 MVP로서 좋은 선택이었다고 생각한다. 하지만 도도카트는 1년을 넘어 2년을 향해 나아가고 있고 어느 정도 시장성을 검증하여 더더욱 발전해 나아가기 위해 많은 기능이 추가되고 있다. 그래서 앱과 백오피스가 같은 도메인을 다룸에도 명확하지 않은 명세와 다르게 동작하는 기능들, 그리고 여기저기 산재하여 있는 중복된 코드들로 서비스의 속도를 저해할 요소들을 제거할 필요가 있었다.
그리고 도메인에 대해 정리된 문서가 없다 보니 특정 도메인이 어떤 역할을 담당하는지 주요 도메인이 어떤 도메인인지 각 도메인이 어떤 상호작용을 하고 있는지 파악하기가 쉽지 않았다. 새로운 기능 개발 시마다 기획문서가 있긴 하였지만, 그 문서는 특정 기간 내에 새롭게 추가한 기능에 관한 내용만 있을 뿐 도메인이 가진 전체 기능을 파악하기에는 어려움이 있었다.
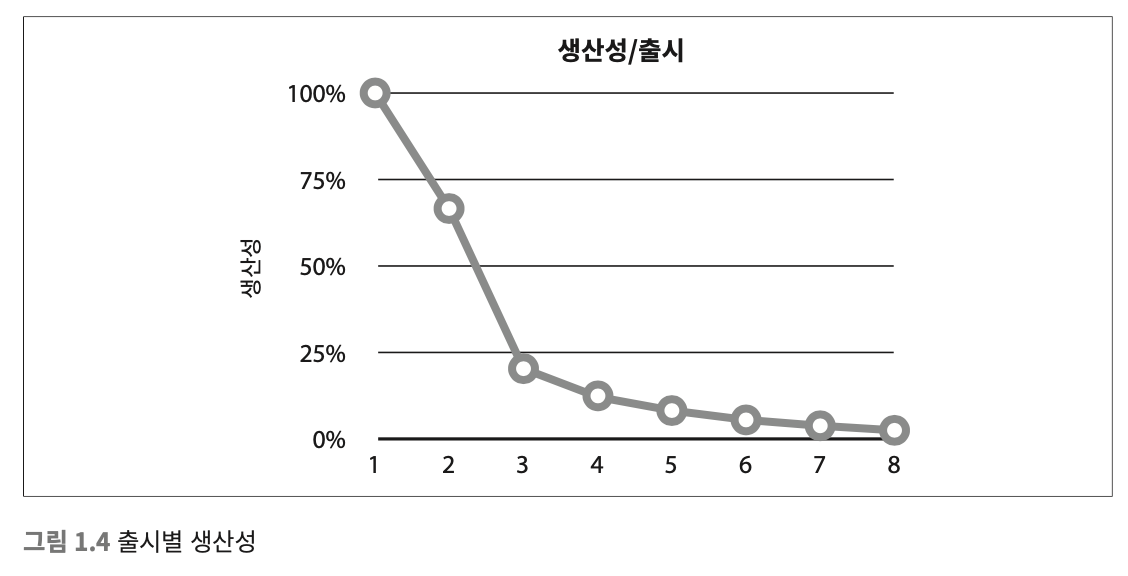
위 사진은 클린아키텍쳐에서 소개된 시스템을 급하게 만들거나 코드와 설계에 대한 고민 없이 제품이 만들어졌을 때 개발자 인원이 늘어나면서 인원당 생선성을 볼 수 있는 그래프이다.
시간이 지남에 따라 우리가 수행해야 할 요구사항은 늘어갈 것이고 백엔드에 속해있는 프로그래머의 수는 더욱 많아 질 것이다. 내가 생각했을 때 구조 개선을 수행하지 않으면 도도카트도 위 그래프와 같은 상황을 마주칠 가능성이 높아 보였다. 그래서 현재의 생산 성을 미래에 투자하기로 하였다.
목표
스포카에서는 주기적으로 아젠다가 모이면 크리에이터 워크샵을 개최한다.크리에이터는 제품을 개발하는 구성원으로 PO, PM, 디자이너, 개발자, 데이터엔지니어, QA 등을 모아 지칭 그룹을 말한다. 워크샵에서 크리에이터 분들에게 도메인에 대한 중요성을 부각하고 모두가 이 도메인 잘 정의하고 관리하기 위한 내용으로 발표를 진행하였다.
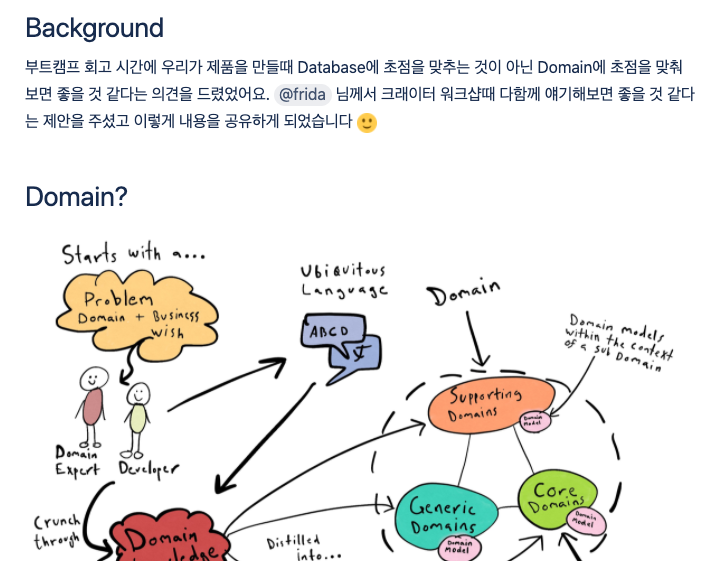
도메인 문서의 궁극적인 목표는 도도카드 제품을 만드는 모든 크리에이터들이 보고 참고하실 수 있는 범용적인 도메인 문서를 작성하는 것이다. 하지만 먼저 백엔드에서 제공하는 기능을 기반으로 도메인 문서를 먼저 작성해보기로 하였다.
로드맵 정의
문제를 정의했으니 실천계획을 잡을 단계가 왔다. 아무래도 작업에 대한 예시를 보여주면 좀 더 와 닿을 것 같기도 해서 백엔드 프로그래머들이 먼저 백엔드 서비스의 도메인을 정의하고 문서로 정리하기로 하였다. 문서를 정의한 후에는 이 문서를 기반으로 백엔드 서버의 코드 구조를 개편하고 도메인이 가진 행위들을 새롭게 구현하기로 하였다.
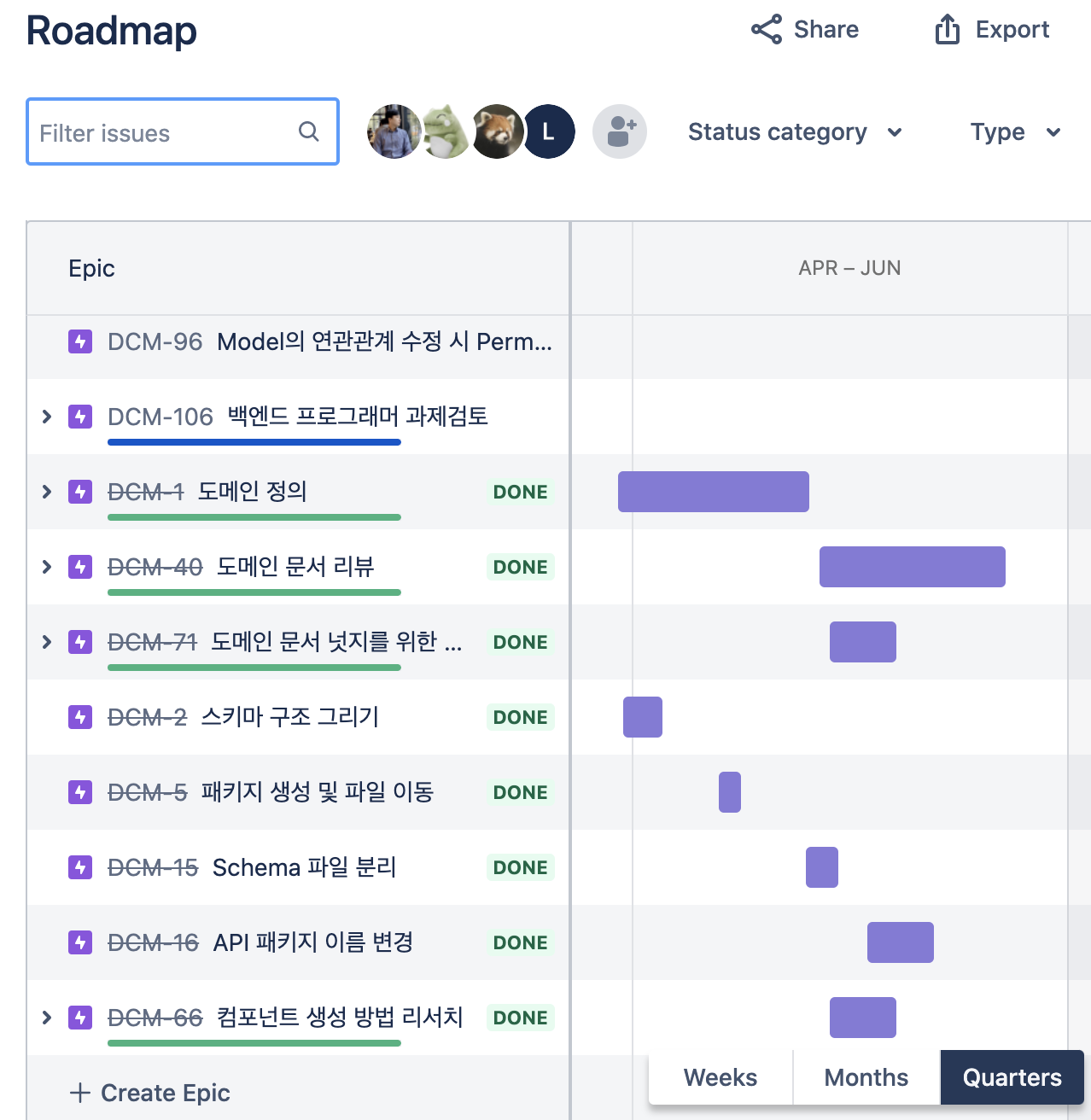
도도카트는 현재에도 성장을 이어가고 있기 때문에 기능 개발을 함께하면서 틈나는 시간마다 백엔드 서버의 전반적인 구조 개편을 하기 위한 로드맵을 정하였다. 기간을 명확하게 정하긴 어려웠지만 넉넉한듯하면서 너무 여유롭지 않은 기간(??)으로 로드맵을 작성하였고 해당 기간 내에 정해진 작업을 완수하기 위한 노력을 이어갔다. 팀에서는 애자일의 스크럼 방식으로 서비스를 개발하고 있는데 스프린트마다 작업시간을 할당할 때 버퍼시간이라고 해서 예기치 않은 운영 이슈나 QA이슈 대응 그리고 지속적인 리펙토링을 위한 시간으로 활용하고 있다. 그래서 지금 이 프로젝트도 그 시간을 적극 활용하였다.
도메인 정의
도메인 문서를 작성하기 위해서 사전에 백엔드 개발자들과 구현방법 공유 및 의견을 주고받는 자리를 마련하였고 일관성 있는 문서 양식을 유지하기 위해 내가 먼저 선행적으로 하나의 도메인을 선택해 템플릿 역할을 할 수 있도록 문서를 작성한 후 다른 개발자들이 해당 문서를 참고 해서 각자 도메인을 나누어 작성하는 방법으로 문서를 작성해 나갔다.
주요 도메인 정의
가장 먼저 주요도메인 정의를 먼저 하였는데, 도메인 주도 설계에서 보면 Root Aggregate 즉 주요 도메인은 하위 도메인의 관리뿐만 아니라 대부분의 로직을 포함하고 있기 때문에 중요한 역할을 담당한다. 그래서 현재 구현되어있는 도메인들을 나열하고 이중에 주요 도메인을 추출하여 정리하는 작업을 선행하였다.
행위 정의
도메인을 나열하고 난 후 도메인별로 행위를 적어보았다. 괜찮은 접근법인지는 모르겠으나 일단은 테스트 코드가 작성되어있는 API를 기준으로 도메인들의 행위들을 작성하는 방법을 채택하였다. (테스트 코드가 각 도메인이 가진 행위를 정리하는 데 아주 큰 도움이 되었다.) 그런 다음 각 행위를 명령과 조회로 구분하였다. 명령과 조회로 구분한 이유는 CQS에 모티브한 것으로 명령과 조회의 역할을 나눔으로써 좀 더 명확하게 행위를 구분하고 컨텍스트를 묶어주기 위함이다.
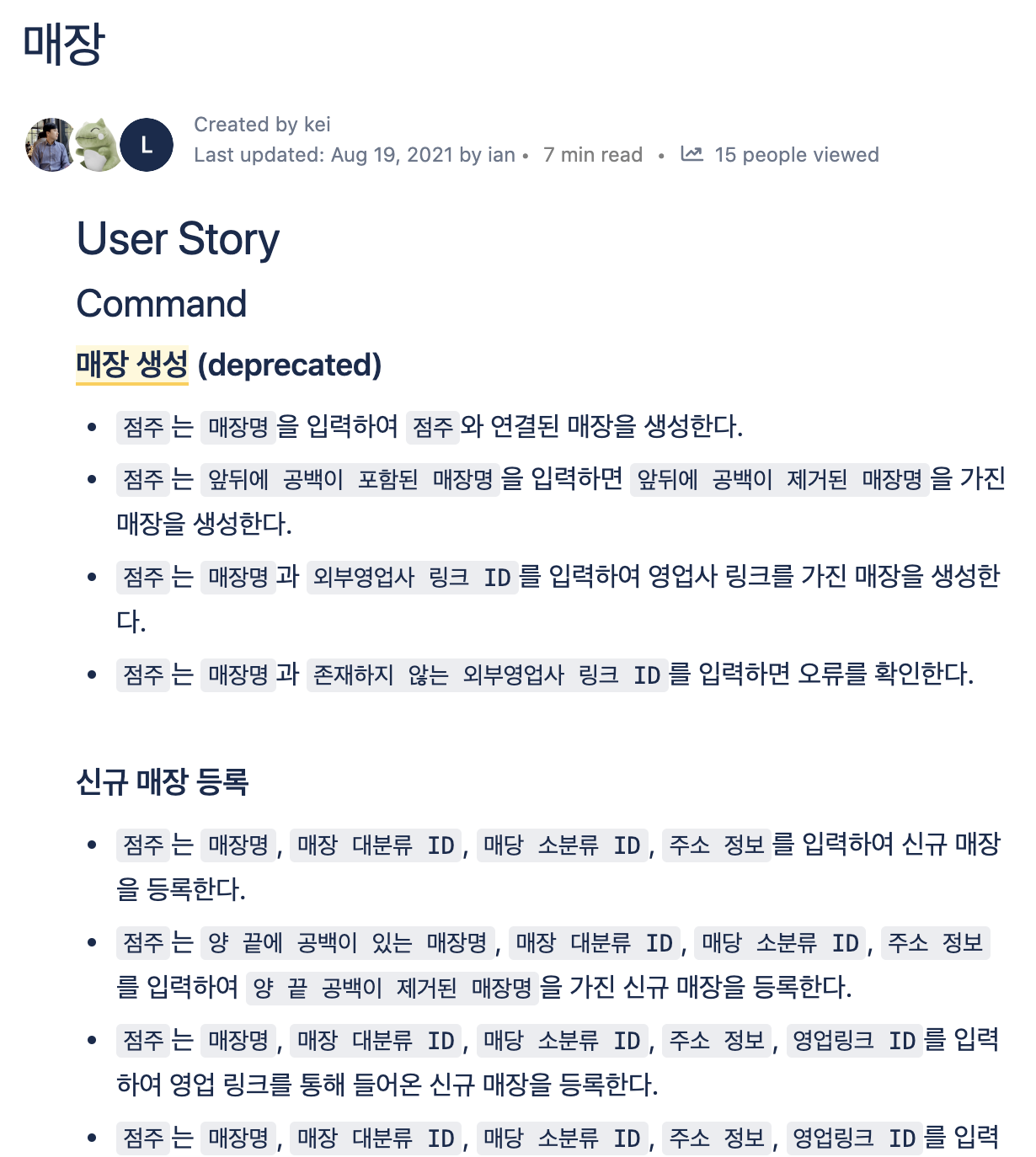

속성 정의
속성은 주요 도메인이 가진 상태를 표현한다. 현재는 도메인 문서가 백엔드를 기준으로 작성되다 보니 속성을 정의해 놓았는데 추후 서비스 전체에 대한 도메인 문서로 발전했을 때 필요 여부는 그때 다시 한 번 판단해 보아야겠다.
리뷰
문서를 다 작성한 후에는 문서에 대한 리뷰를 통해서 혹시나 빠지거나 개선해야 할 부분이 없는지에 대해서 리뷰를 진행하였다.
패키지 구조 변경
구조를 변경하기 이전의 패키지 구조는 기능별로 나누어져 있었는데 ORM의 Entity 별로, GraphQL Schema 별로, 셀러리 등 서드파티나 권한 설정 등으로 구성되어 있었다. 이러한 구조는 처음 작은 기능들로 구성된 프로젝트에서는 단순하고 명확하게 구분 지어서 사용하기에 좋았지만 어플리케이션이 점점 커진다면 도메인별로 응집력 있게 코드가 모여서 제공하는 기능을 명확하게 파악할 수 있는 구조로 나아가기에는 한계가 있어 보였다.
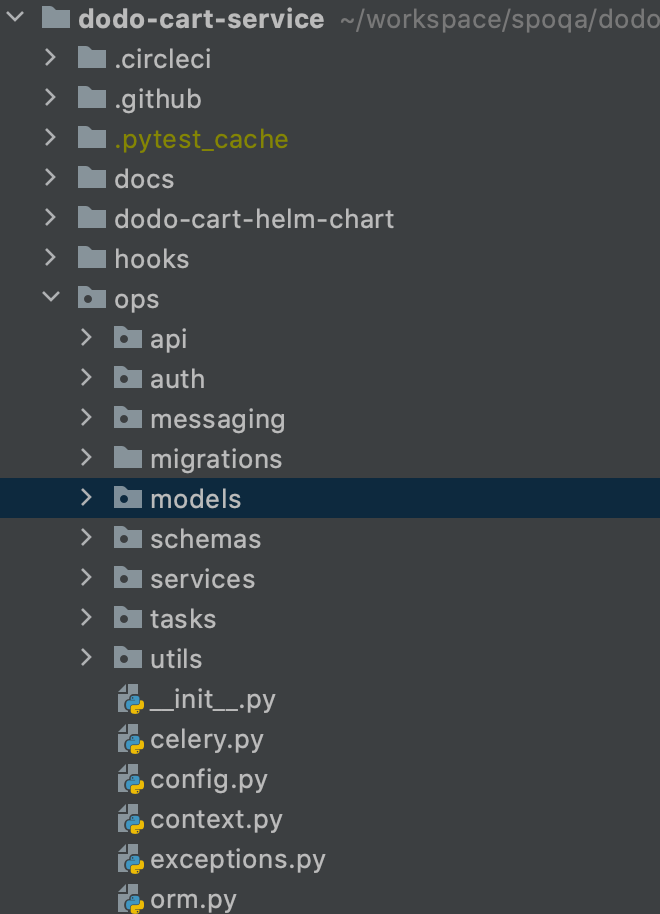
그래서 패키지 구조를 변경하기로 하였고 도메인 정의를 하면서 주요 도메인을 먼저 정의하고 난 이후에 패키지 구조를 함께 변경할 수 있을 것 같아서 패키지 구조를 함께 변경하기로 하였다. 개발자끼리 각자 좋을 것 같다고 생각하는 구조를 먼저 찾아본 후 서로 비교하고 가장 마음에 구조를 아래와 같이 선택하였다.

전체 패키지 구조
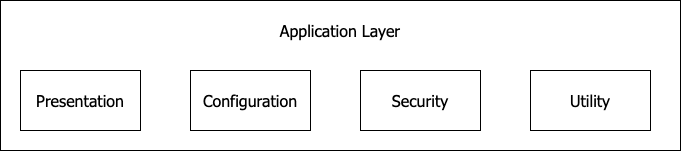
전체 패키지 구조는 Layered architecture를 따르도록 하였다. Domain Driven Design과 Clean Architecture를 참고 해서 프리젠테이션, 어플리케이션, 도메인, 인프라스트럭쳐 4개의 레이어를 나누려고 생각하였지만, 아직 익숙하지 않은 분들을 위해서 덜 복잡한 구조를 가지도록 프리젠테이션과 어플리케이션를 합쳐서 어플리케이션으로 그리고 인프라스트럭쳐와 도메인으로 나누어 3개의 레이어를 가지도록 단순화하였다.
의존성 방향은 아래 그림과 같이 어플리케이션이 인프라스트럭쳐와 도메인을 바라보도록 정하였다. 다만 파이썬에서는 의존성 방향은 물리적으로 강제할 방법이 딱히 없으므로 코드리뷰를 통해 개발자들이 서로 의존성 방향 정책을 위반하지 않는지 챙기기로 했다.
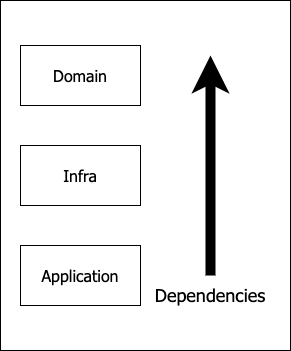
도메인 레이어
도메인 레이어는 클린아키텍쳐에서 소개한 컴포넌트 기반 패키지 구조를 가지도록 하였다. 어플리케이션 레이어에서는 도메인을 사용할 때 반드시 Component를 통해서만 기능을 수행하도록 함으로써 의존성을 우회하지 않도록 정하였다.
이 구조의 장점은 도메인 코드들이 응집도 있게 모여있도록 할 수 있고 경계를 명확히 해준다는 장점이 있다. 그리고 Component를 통해서만 기능을 수행하도록 강제함으로써 도메인을 사용하는 코드들이 도메인이 제공하는 기능에 일관성을 기대할 수 있고 코드를 단순히 할 수 있다는 장점이 있다.
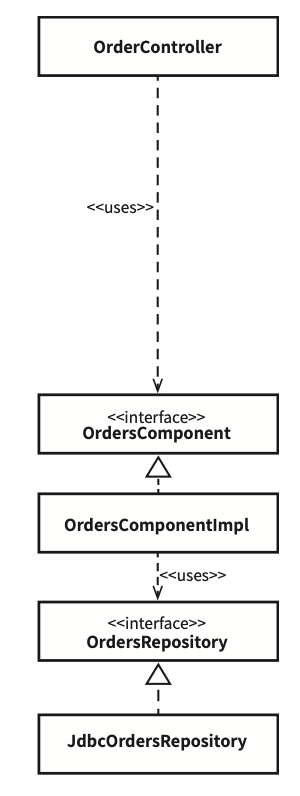
한편 도메인 레이어는 어플리케이션 레이어의 어느 코드도 의존해서는 안 되는데 이는 순환참조를 방지하고 코드의 복잡성을 낮추기 위함이다. 다만 ORM을 사용하다 보니 어쩔 수 없이 SQLAlchemy에 대한 의존성을 가질 수밖에 없어서 해당 의존성은 예외로 두었다. 도메인 모델과 영속성 모델을 분리해서 이를 해결할 수 있겠으나 복잡해질 수 있으므로 고려대상에서 제외하였다.
이 부분에 대해서 추가로 얘기하자면 DDD에서 보면 인프라스트럭쳐는 도메인보다 더 중심에 있고 도메인이 인프라스트럭쳐를 의존하고 있는 모양을 취하고 있다. 반면 클린 아키텍쳐에서는 인프라스트럭쳐에 대한 의존성은 도메인보다 바깥에 있도록 하라고 말하고 있다.
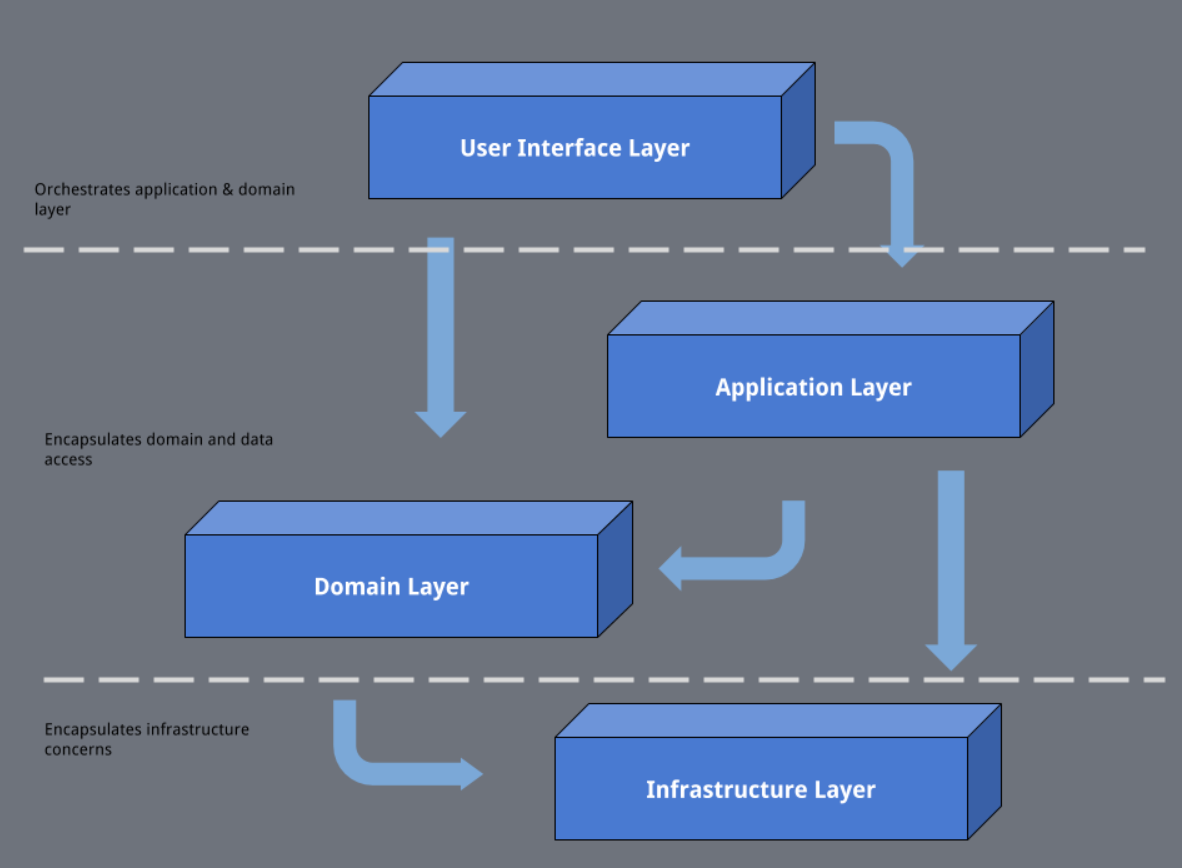
개인적으로는 프레임워크를 사용하고 특히 ORM을 사용하고 있다면 DDD에서 보여준 구조가 좀 더 좋아 보인다. 클린아키텍쳐의 구조가 이상적일 순 있으나 불편한 부분이 상당히 많이 있고 성능적인 부분(lazy loading 등)도 일부 포기해야 하는 일도 발생하기 때문이다.
어플리케이션 레이어
어플리케이션 레이어는 패키지 구조를 횡단으로 가지는 기능 기반 구조를 가지도록 하였다.
이 구조의 장점은 기능별로 패키지를 나눌 수 있어 쉽게 이해할 수 있고 명시적이어서이다. 도메인 레이어와 같이 각 클래스 또는 파일들이 응집력 있게 유지하면서 경계를 철저하게 나누어야 할 필요성이 크지 않으므로 단순히 구조를 설계하면 좋을 거라 생각했다.
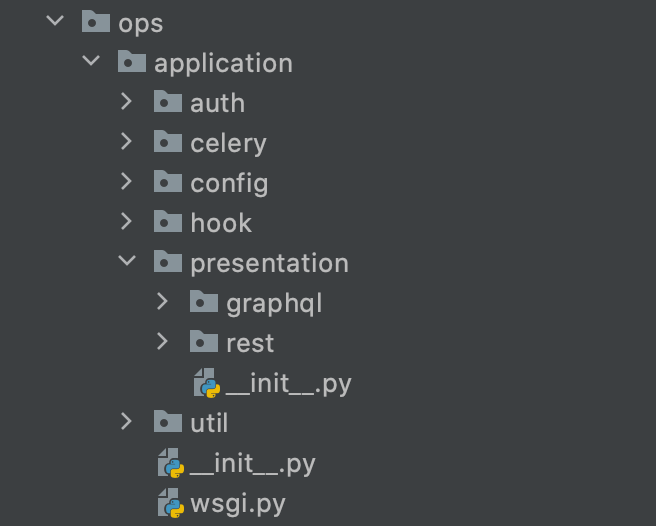
어플리케이션 내 프리젠테이션 레이어는 GraphQL 스키마들이 모여 있고 일부 Rest API의 Controller도 포함되어 있다. 그 외 프로젝트를 위한 설정 값들도 이 레이어에 있다.
필요하다면 이 레이어에서 어플리케이션 서비스들을 가질 수 있다. 도메인 레이어의 서비스와는 조금 결이 다른데 도메인 서비스는 해당 도메인에 대한 주요 비지니스 로직을 다룬다면 어플리케이션 서비스는 도메인 서비스들을 모아서 사용하도록 하는 Facade 객체나 외부 서드 파티 라이브러리 등을 사용하는 서비스라 생각하면 된다.
인프라 레이어
어플리케이션 레이어도 어플리케이션 레이어와 같이 기능 기반 구조를 가지도록 하였다.
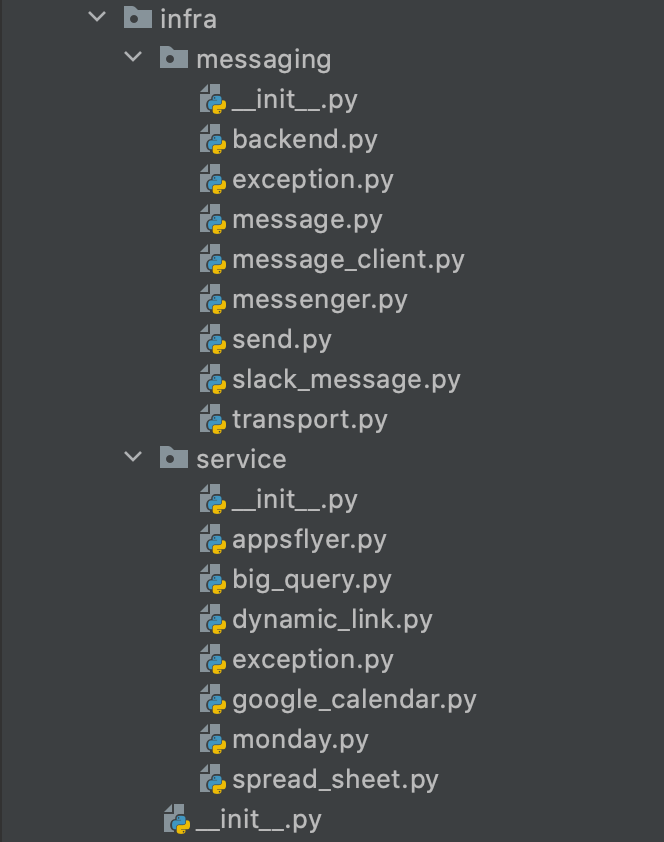
주로 Third party library들을 모아서 관리하는 레이어이다. 이 레이어는 DDD나 Clean Architecture에서 말하는 인프라와는 다른 용도로 사용된다. 그래서 처음 레이어를 나눌 때에는 느끼지 못했지만 조금 모호함이 있다고 느껴져서 바꾸면 어떠하겠느냐는 생각이 든다.
Model의 행위를 좀 더 풍부하게
도메인 주도 개발에서의 핵심은 도메인 모델이라 생각한다. 그래서 난 모델이 가진 행위가 풍부해야 한다고 생각한다. 길지 않은 개발 경험이지만 어플리케이션을 위한 코드들에서 도메인 모델은 데이터 속성만 정의되어 있고 서비스 클래스가 대부분 행위를 수행하는 것을 자주 보았다. 이는 Database 중심의 개발에서 흔히 볼 수 있는 사례들로 Entity Model을 Database의 테이블 속성을 나타내는 용도 이외로는 생각하지 않아서라 판단된다.
ORM의 사용이 활발해 지면서 이러한 문제는 많이 개선되었다. Entity Model이 더는 Database의 상태를 위한 객체가 아닌 하나의 도메인으로 역할과 책임을 수행하는 주체로 변화한 것이다.
마이크로 서비스 패턴에서 소개한 다이어그램이 있는 데 Entity Model이 주요 로직을 가지고 Service 클래스가 해당 로직을 사용하는 모습을 잘 보여준다고 생각해서 소개해 본다.
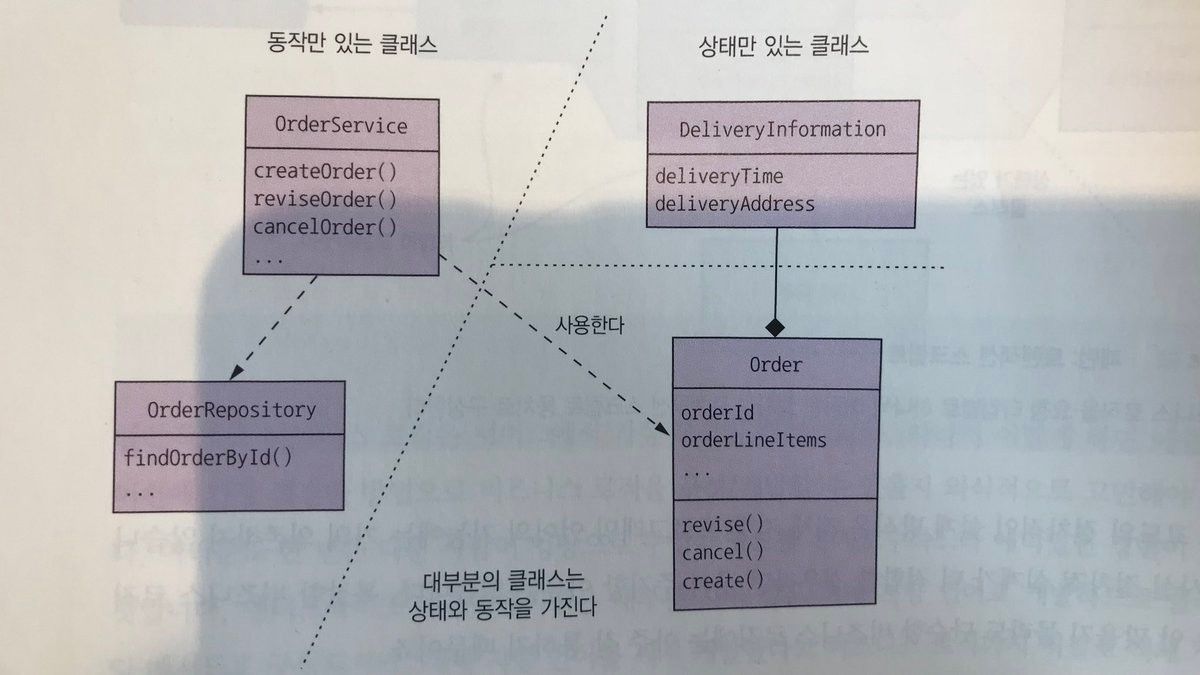
다이어 그램만 본다면 이해가 쉽지 않을 수 있으니 코드 예제도 함께 소개해 보겠다.
Service에 비지니스 로직이 모두 존재하는 코드
class ManagerService:
def withdraw(self, manager_id: uuid.UUID, store_id: uuid.UUID):
"""매장을 탈퇴합니다."""
manager = self.get_by_id(manager_id)
stores = [store for store in manager.stores if store.id == store_id]
if not stores:
raise EntityNotFound(ManagerStoreAssoc)
manager.stores.remove(stores[0])
Entity에 비지니스 로직이 존재하고 Service는 Entity의 함수를 사용하는 코드
class ManagerService:
def withdraw(self, manager_id: uuid.UUID, store_id: uuid.UUID):
"""매장을 탈퇴합니다."""
manager = self.get_by_id(manager_id)
manager.withdraw_store(store_id)
class Manager(base):
## 생략...
def withdraw_store(self, store_id: uuid.UUID):
"""매장을 탈퇴합니다."""
stores = [store for store in self.stores if store.id == store_id]
if not stores:
raise EntityNotFound(ManagerStoreAssoc)
self.stores.remove(stores[0])
Service에 비지니스 로직이 모두 존재하는 코드와 Entity에 비지니스 로직이 존재하는 코드는 수행 결과는 크게 다르지 않다. 다만 Entity에 로직이 존재하는 경우 자신의 상태를 변경하도록 하기에 상태를 캡슐화하기 좋다. 그리고 예시에서는 단순한 코드를 보여주었지만, Service 코드는 비대해지고 복잡해지기 쉽다. Entity에 수행하는 비지니스 로직들을 가지고 Service는 이를 사용하도록만 하더라도 코드의 복잡성과 가독성이 아주 많이 개선되는 것을 볼 수 있을 것이다. 또한 Entity를 사용하는 어느 Service라도 Entity가 가진 행위를 재사용할 수 있다는 장점도 있다.
위와같은 이유로 기존에 존재하던 비지니스 로직들을 Entity로 가져오는 작업에 공을 많이 들였다.
Service와 Repository 생성
기존 패키지 구조에서 가장 고치고 싶었던 부분이 바로 비지니스 로직이 Resolver 즉 프리젠테이션 레이어에 위치하는 것이었다. 이는 도메인이 가진 공통된 로직이 여기저기 Resolver마다 위치하게 되어 중복된 코드와 응집도가 떨어지게 되면서 같은 기능이 API가 사용되는 곳마다 다르게 동작하는 문제점을 일으키고 있었다.
아래 코드는 코드를 고치기 전 Resolver에서 사용하던 코드 일부이다. SQL Alchemy의 쿼리가 그대로 사용되면서 각 코드가 어떤 목적을 위한 행위를 하는지 알기 위해서는 코드 하나하나를 뜯어보아야 하는 문제가 있다. 그리고 Resolver가 디테일(SQL Alchemy)에 그대로 의존하고 있으며 앞에서도 언급했지만 같은 로직을 재사용하기 어려운 구조로 되어있었다.
def mutate(
root,
info: ResolveInfo,
*,
input: AssignReceiptImageGroupInput,
):
admin_id = get_admin_id()
if not admin_id:
raise Forbidden
admin = session.query(Admin).with_for_update(
skip_locked=True
).get(admin_id)
if not admin:
raise ObjectNotFound(class_=Admin)
assigned_receipt_image_group = session.query(
session.query(ReceiptImageGroup).filter(
ReceiptImageGroup.assigned_admin_id == admin.id,
~ReceiptImageGroup.processed,
).exists()
).scalar()
if assigned_receipt_image_group:
raise AlreadyAssignedReceiptImageGroup
group_type = ReceiptImageGroupTypeModel(input.group_type)
query = session.query(ReceiptImageGroup).filter(
ReceiptImageGroup.group_type == group_type,
~ReceiptImageGroup.processed,
~ReceiptImageGroup.assigned,
session.query(ReceiptImageUrl).filter(
ReceiptImageUrl.get_group_id_column(group_type) ==
ReceiptImageGroup.id,
).exists(),
)
receipt_image_group = query.order_by(
ReceiptImageGroup.created_at.asc(),
ReceiptImageGroup.id.asc(),
).first()
if not receipt_image_group:
raise ObjectNotFound(class_=ReceiptImageGroup)
receipt_image_group.assigned_admin_id = admin.id
session.commit()
return AssignReceiptImageGroup(receipt_image_group=receipt_image_group)
그래서 패키지 구조를 위에서 설명한 대로 나눈 후에 도메인별로 Service와 Repository를 만들어주고 도메인과 관련한 비지니스 로직은 Service 클래스에 영속화와 영속화된 데이터를 조회하는 코드는 Repository에 넣어서 SRP를 지키고자 하였다.
여기서 문제는 기존에 이러한 Component 객체가 없다 보니 Service와 Repository 클래스의 생명주기를 효율적으로 관리하는 방법을 따로 모색해야 했다. Spring에서는 기본적으로 IoC Container가 이를 관리해 주지만 현재 도도카트 서비스는 경량 프레임워크인 Flask를 기반으로 하고 있기 때문에 이러한 관리 기능이 따로 없었다. 그렇다고 DI 라이브러리를 이용하자니 라이브러리가 제공하는 기능에 비해 우리가 사용하고자 하는 기능이 극히 일부에 불과했고 그러다 보니 라이브러리들을 사용하기 위한 코드들이 장황하게 느껴졌다. 그리고 Graphene 필드 내부에도 Resolver들이 위치하다 보니 사용 가능 여부도 판단해야 하는 등 적용 공수가 적지 않으리라고 판단해서 Component의 생명주기를 관리하기 위한 데커레이터를 추가해서 사용하기로 했다. 해당 데커레이터는 단순히 Singleton과 같이 처음 호출 시 Component를 생성하고 그 이후에는 클로저 내부의 자유변수에 생성한 컴포넌트를 캐싱하여 이후 컴포넌트 생성 시 캐싱된 컴포넌트를 가져오도록 하는 구실을 한다.
def component(func: Callable) -> Callable:
components = {}
@functools.wraps(func)
def wrapper(*args, **kwargs):
name = func.__name__
cached_component = components.get(name)
if cached_component:
return cached_component
components[name] = func(*args, **kwargs)
return func(*args, **kwargs)
return wrapper
변경된 Resolver 코드는 아래와 같다. Resolver에서 한번의 요청으로 도메인 로직을 수행하도록 모아주는 Facade 등과 같은 클래스가 없어서 눈에 띄게 단순해지진 않았지만 각 코드가 무엇을 수행하는지 함수명만으로도 어느 정도 유추할 수 있으며 각 레이어 마다 각자 수행하는 로직을 명확히 구분함으로써 하나의 책임을 가질 수 있게 되었다. 그리고 만약 같은 기능이 다른 Resolver에서 필요하다면 언제든지 재사용할 수 있게 되었다.
def mutate(root, info: ResolveInfo, *, input_: AssignReceiptImageGroupInput):
if not (admin_id := get_admin_id()):
raise Forbidden
try:
admin_service().get_skipped_lock_admin_by_id(admin_id)
except EntityNotFound:
raise ObjectNotFound(class_=Admin)
receipt_service_: ReceiptService = receipt_service()
assigned_receipt_image_groups = receipt_service_.get_assigned_receipt_image_groups(admin_id)
if assigned_receipt_image_groups:
raise AlreadyAssignedReceiptImageGroup
try:
receipt_image_group = receipt_service_.get_assignable_receipt_image_group(group_type=input_.group_type)
receipt_service_.assign_admin_to_receipt_image_group(receipt_image_group.id, admin_id)
return AssignReceiptImageGroup(receipt_image_group=receipt_image_group)
except EntityNotFound:
raise ObjectNotFound(class_=ReceiptImageGroup)
Query Field 분리
현재 도도카트 백엔드 서비스는 GraphQL을 위해 Graphene을 ORM을 위해 SQL Alchemy를 사용하고 있다. 그리고 이 두 라이브러를 손쉽게 통합해서 사용할 수 있는 graphene-sqlalchemy라이브러리를 사용하고 있다. graphene-sqlalchemy를 사용하면 GraphQL 스키마를 아주 손쉽게 만들 수 있는데 왜냐하면 Entity만 정의되어 있으면 그것에 맞게 알아서 라이브러리가 스키마를 만들어주기 때문이다.
이 또한 처음 개발할 때 MVP 용도로는 이만한 게 없다고 생각한다. 하지만 이 라이브러리를 사용함으로써 아래와 같은 문제가 생긴다.
레이어가 분리되어 있지 않다.
우리가 API서버를 사용하는 가장 큰 이유 중 하나가 바로 캡슐화라고 생각한다. 내부 데이터(DB, 로직, 상태 등등)를 숨기고 필요한 인터페이스만 제공함으로써 클라이언트의 잘못된 사용으로부터 데이터를 보호하고 숨기고자 하는 데이터는 숨기고 필요한 정보만 제공하는 역할을 하는 것이다. 하지만 graphene-sqlalchemy라이브러리는 sqlalchemy의 Model 정보를 그대로 query field를 통해 노출한다. 물론 신경을 쓴다면 어느 정도 노출은 막을 수 있겠으나 SQLAlchemyObjectType를 통해 너무도 쉽게 query field를 만들 수 있기 때문에 개발자가 자신도 모르게 Model을 Field로 사용하는 우를 범한다.
레이어 분리가 되어있지 않는 또 다른 사례가 있는데, 바로 Presentation Layer에서 SQLAlchemy의 Query를 직접 사용한다는 것이다.
graphene-sqlalchemy의 UnsortedSQLAlchemyConnectionField.resolve_connection를 보면 아래와 같이 코드가 작성되어 있다.
@classmethod
def resolve_connection(cls, connection_type, model, info, args, resolved):
if resolved is None:
resolved = cls.get_query(model, info, **args)
if isinstance(resolved, Query):
_len = resolved.count()
else:
_len = len(resolved)
connection = connection_from_list_slice(
resolved,
args,
slice_start=0,
list_length=_len,
list_slice_length=_len,
connection_type=connection_type,
pageinfo_type=PageInfo,
edge_type=connection_type.Edge,
)
connection.iterable = resolved
connection.length = _len
return connection
코드를 보면 알겠지만 connectionField를 생성할 때 SQLAlchmey의 Query 결과를 기반으로 한다는 것을 볼 수 있다. 이는 Resovler가 Repository의 책임도 함께 하도록 유도하고 있으며 (심지어 가이드 문서에서 조차 예제로 resolver에서 query를 작성하고 있다.) 이는 코드의 중복을 증가시키고 재사용성을 현저하게 떨어뜨리는 앞에서 언급한 그 문제를 일으킨다. 아주 작은 어플리케이션에서는 이 방법이 매우 빠르고 실용적일 순 있겠지만, 도메인이 조금만 커지면 resolver 여기저기 산재하여 있는 비슷하거나 같은 쿼리들을 변경하고자 할 때와 공통 로직을 변경해야 할 때 그 고통은 말로 표현할 수 없을 것이다.
확장성이 떨어진다.
최근 특정 도메인에서 제공하던 Query를 하나의 테이블에서 두 개의 테이블정보를 합쳐서 보여주도록 변경하는 작업을 하고 있다. 기존의 인터페이스를 변경하지 않고 즉, Query Field는 변경하지 않고 내부 로직만 바꾸면 클라이언트로서는 전혀 손을 대지 않고 기능의 변경을 꾀할 수 있다.
하지만 지금 서버의 코드에서는 위와 같은 방법을 바로 적용하기가 쉽지 않았다. SQLAlchemyObjectType은 Model에 종속적이기 때문에 다른 테이블의 정보를 합쳐서 보여주기 어렵다. 왜냐하면, Model은 대부분 하나의 (RDB를 기준으로)테이블 정보를 가지고 있기 때문이다.
또한 위에서 언급한 것처럼 Query를 기반으로 Connection Field를 만드는 부분 때문에 두 개의 조회 결과를 넘길 수 있는 좋은 방법이 없었다. (union all을 사용하여서 할 수 있다고 생각하지 말자… DB 쿼리 중심적인 설계는 나중에 큰 발목을 잡을 것이다.)
그래서 우리는 기존의 SQLAlchemyObjectType을 Graphene의 ObjectType으로 변경하는 작업을 선행하고 Connection Field를 새롭게 만들어 SQLAlchemy의 Query에 종속적이지 않도록 변경하는 작업을 하고 있다. 이렇게 변경하고나면 외부 인터페이스를 변경하지 않고도 내부코드(DB 스키마를 포함해서)를 자유롭게 변경할 수 있다.
위와 같은 이유로 SQL Alchemy와 연결된 Query Field들을 분리하기로 했다.
분리방법은 큰 특이점은 없고 Query Field를 새롭게 정의하는 것이다. 다만 Connection은 새롭게 만들어주어야 했는데 SQL Alchemy Connection을 참고 해서 필요한 부분만 새롭게 만들어주었다.
class ConnectionField(Field):
def __init__(self, type_, *args, **kwargs):
kwargs.setdefault('first', Int())
kwargs.setdefault('offset', Int())
kwargs.setdefault('after', String())
super(ConnectionField, self).__init__(type_, *args, **kwargs)
## 생략...
def get_resolver(self, parent_resolver):
resolver = super(ConnectionField, self).get_resolver(parent_resolver)
return functools.partial(self.connection_resolver, resolver, self.type)
## 생략...
Wrap up
아직 모두 다 완벽하게 완수하진 않았지만 많은 구조개선을 하였고 현재 가진 문제를 지속해서 해결해 가고 있다. 앞에서 설명한 것 중 어플리케이션 레이어의 서비스는 아직 추가하지 않았는데 이유는 개발자들이 도메인 서비스와 어플리케이션 서비스의 역할을 정의할 때 혼란이 있을까 걱정되어서이다. 이 부분은 추후 도메인 코드들 정리가 되면 추가로 구조개선을 하기로 하고 일단 Resolver에서 해당 부분을 구현하기로 하였다.
이번 전환 활동을 통해서 좀 더 빠르고 자세하게 도도카트에 대해 이해할 수 있게 되었고 코드를 개선하면서도 모호했던 기능들이 각자의 역할별로 나누고 응집력 있는 코드들로 개선하게 되면서 좀 더 높은 유지 보수성을 가진 백엔드 서비스로 나아갈 수 있었다. 그리고 큰 걱정 없이 패키지 구조와 코드의 구조를 개선할 수 있었던 건 테스트 코드가 잘 작성되어 있었기 때문인데 이번 경험을 계기로 테스트 코드의 힘을 다시 한 번 느낄 수 있었다.
새롭게 서버 코드를 구성하는 것이 아니라 기존에 작성되된 코드를 더 나은 방향으로 개선하는 작업은 이번이 처음인데 구조에 대한 고민과 효율적인 선택을 하는 고민을 하는 경험을 할 수 있어서 뜻깊은 프로젝트였던 것 같다.
그리고 문서의 유지관리에 대한 우려는 아직 숙제로 남아 있다. 기획문서와의 통합또한 마찬가지로 앞으로 해야할 일이다. 앞으로 진짜 개발자뿐만 아니라 크리에이터 모두의 노력이 필요한 시점이 올 것이다. 이 숙제를 해결해 가고 좋은 문서를 만든 경험을 쌓는 것 또한 좋은 경험이 되리라 생각된다.
베스트 사례라고 말하긴 어렵지만, 더 나은 제품을 만들어가기 위한 고민을 하고 있다면 참고할 만한 자료가 되었길 바란다.