
2021년 8월 개발일지
8월은 입사 이래로 참 다사다난했던 월이었다.
팀장님이나 임원진 분들은 미리 알고 있으셨겠지만, 기존 멤버의 갑작스러운 퇴사 소식이 그 첫 번째 이다. 무엇보다 안타까운 점은 그 누구보다 열심히 제품 개발에 힘써 주시고 많은 일을 해오셨기 때문에 그 빈자리가 더욱더 아쉽게 느껴졌다. 다른 곳으로 이직하는 것은 아주 축하해줄 일이지만 정이 쌓이기도 전에 이렇게 헤어짐이 있다는 것은 다소 아쉽긴 하다.
두 번째는 거래처 TF로 팀을 옮긴 것이다. 사실 크게 달라진 건 없다. 백 엔드 챕터의 리더로써 팀의 백 엔드의 개발 방향이나 코드 퀄리티는 계속해서 챙겨야 하고 오거나이저로써 팀 내 프로그래머의 티켓 관리 및 리소스 관리를 해야 한다. 거기에 거래처 TF로 옮기면서 거래처 TF의 백 엔드 개발을 해야 하는 역할까지 추가로 부여된 것이다.
상황이 녹록지 않지만 할 수 있는 데까진 최선을 다해보고자 한다. 다만 어느 것 하나 제대로 하는 것이 없을까 걱정이다. 일단 8월 중에는 그럭저럭해내곤 있다.
세 번째는 검색엔진 장애이다. 참 아이러니하게도 기존 멤버가 퇴사하시고 나서 검색엔진에 장애가 발생했다. 히스토리 파악과 코드 분석이 제대로 되지 않았다 보니 장애 기간이 생각보다 길었었다. (임시조치로 해결했었지만 3~4일 정도 재발했었다) 이번 장애로 Elastic Cloud에 대해서 조금이나마 이해를 할 수 있게 되었지만 Elasticsearch에 대해서는 좀 공부를 해야겠다. 무지하다 보니 문제가 발생해도 원인 파악을 제대로 하지 못하고 해결방안 모색 시 뜬구름만 잡는 느낌을 많이 받았다. 역시 아는 것이 힘이다.
네 번째는 도도 카트의 성장이다. 하반기 팀 내 목표치를 상당히 높게 측정하였는데 예상과 달리 8월에 목표치를 달성하게 되었다. 마케팅과 영업의 힘이 컸지만 제품이 시장의 니즈에 잘 맞아떨어진다는 의미로 볼 수 있으니 참 기분 좋은 일이다. 한편으로는 사용자가 많아짐에 따라 생길 이슈를 어떻게 잘 대응할지에 대한 고민도 깊어지기도 하다. 공들여 모셔온 사용자들이 서비스를 잘 이용할 수 있도록 더 나을 서비스를 위한 노력을 꾸준히 이어가야겠다.
아래는 8월 동안 겪었던 개발 내용이다.
WBS
현재 팀 내에서는 JIRA를 통해서 팀의 프로젝트 관리를 하고 있다. JIRA에서는 RoadMap이라는 기능을 통해서 프로젝트의 큰 일정이나 작업 방향을 보여주는 간트차트를 제공해주는데 해당 기능은 아쉽게도 Epic 단위까지만 표시해주지 Task 단위까지는 표시해주지 않고 있어서 실무자들이 실제 스프린트 진행 시 작업에 대한 일정을 관리할 때 Google Excel을 이용하여 WBS를 작성하였었다.
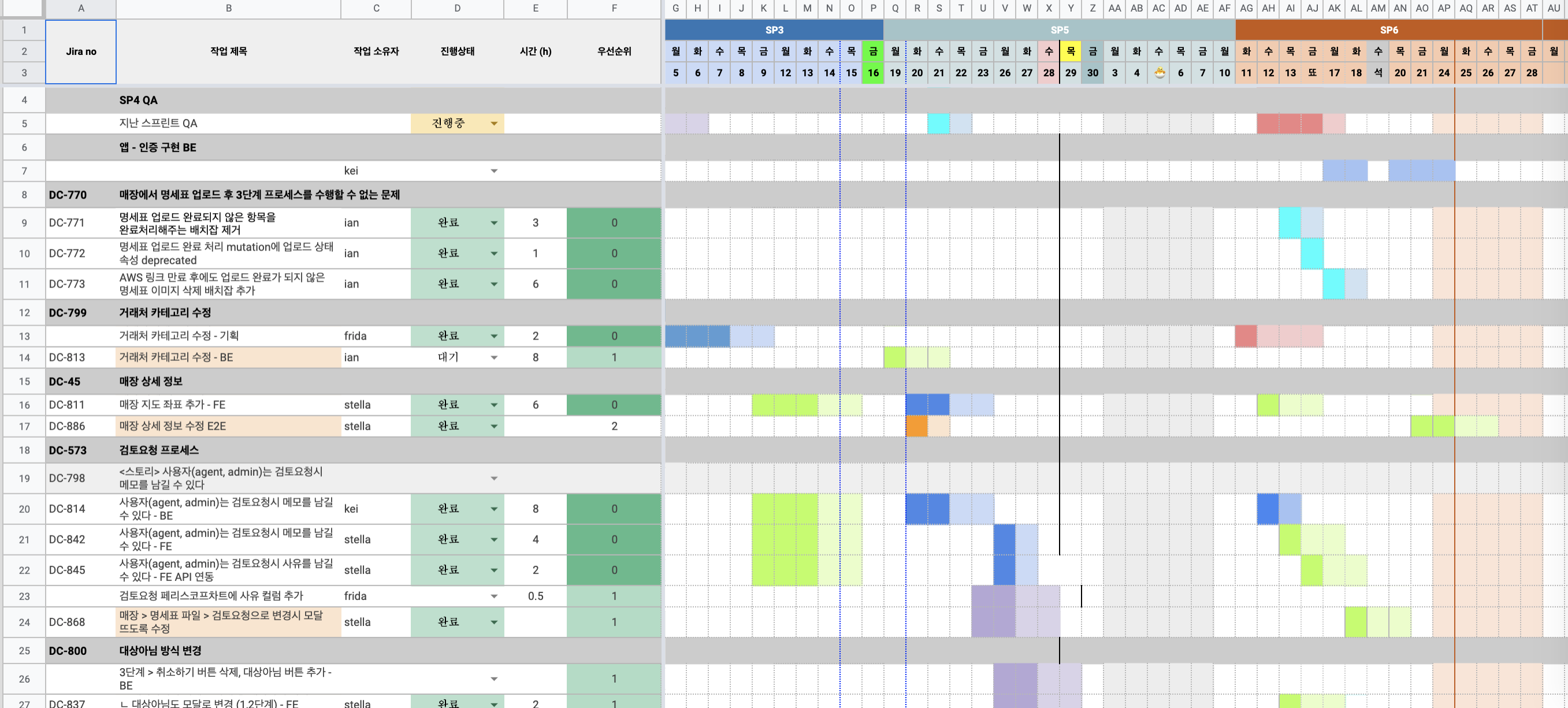
오거나이저 역할을 하면서 팀내 모든 개발자들의 작업 테스크를 관리하면서 Excel에 해당 작업들을 옮겨 적는 작업이 상당히 번거롭고 관리도 잘 되지 않는 문제가 있었다. 그래서 JIRA API를 이용하면 따로 작업하지 않고도 손쉽게 작업을 연동할 수 있으니 JIRA API를 이용한 WBS를 만들어보기로 결심했다.
문제는 UI인데 최대한 WBS와 유사한 UI를 사용해야 팀원들이 불편함을 느끼지 않고 사용할 수 있을 것이라 생각했다. 그러다 발견한것이 바로 DHTMLX Gantt DOC이었다. 다행히 기본기능은 오픈소스로 공개되어있었고 상용으로 쓰지 않는다면 큰 문제는 되지 않을 것으로 보여 사내 WBS UI로 사용하기로 했다.
기능은 상당히 단순한데, 사내 구성원들만 데이터를 볼 수 있어야 하므로 OAuth2를 이용한 로그인 기능을 붙였으며 현재 진행중인 스프린트 내 작업들의 목록을 보여주고 기간이 입력되어 있으면 차트에 표시되도록 구현하였다. 주말동안 간단하게 만들어서 자잘한 버그는 있지만 사내 도구로는 나름 쓸만한것 같다. 그리고 이번에 작업하면서 WebFlux로 OAuth2를 구현해 보았는데 좋은 경험이었다.
프로젝트는 공개해 두었으니 고쳐서 쓰고 싶은분은 쓰셔도 된다.

EC2-Classic 서비스 중단
AWS에서 EC2-Classic 서비스를 중단한다고 한다. 2022년 8월 15일까지라 아직 여유가 좀 있지만 대비할 필요는 있을 듯 하여 EC2 Classic Resource Finder를 이용해서 현재 도도카트 내 사용 리소스가 있는지 찾아보았으나 다행히 없는 것으로 확인되었다. EKS에서 LB로 CLB를 쓰고 있는데 CLB는 포함하지 않나보다.
Graphql on Spring
Spring에서 Graphql을 사용할 수 있는 방법을 찾아보던 중 Netflix에서 만든 라이브러리가 있는 것을 알게 되었다. Netflix 내에서 사용하다가 오픈소스화 한것으로 보인다.
아직 결정은 확실히 되지 않았지만 서버 코드를 Spring으로 전환할지 고민중이기 때문에 Graphql 라이브러리를 좀 찾아보고 괜찮은 것이 있는지 찾아봐야 겠다. 일단 적어도 Graphene을 사용하면서 불편하다고 느꼇던 것들을 해결할 수 있는지 부터 검토해 봐야겠다.
WebClient Buffer Limit
WBS를 작업하면서 생긴 이슈인데, WebClient를 이용하여 JIRA API를 연동하던 중 아래와 같은 오류를 겪게 되었다.
org.springframework.core.io.buffer.DataBufferLimitException: Exceeded limit on max bytes to buffer : 262144
at org.springframework.core.io.buffer.LimitedDataBufferList.raiseLimitException(LimitedDataBufferList.java:101) ~[spring-core-5.2.5.RELEASE.jar:5.2.5.RELEASE]
Suppressed: reactor.core.publisher.FluxOnAssembly$OnAssemblyException:
나와 같은 이슈를 겪은 분의 블로그 글을 통해 Spring에서 기본적으로 버퍼에 대한 제한을 주고 있는 것을 확인할 수 잇었다. 해당 문제는 아래와 같이 버퍼의 제한을 변경하는 방법으로 해결하였다.
WebClient.builder()
.baseUrl(jiraProperties.host)
.filter(ExchangeFilterFunctions.basicAuthentication(jiraProperties.username, jiraProperties.password))
.codecs { it.defaultCodecs().maxInMemorySize(-1) }
.build()
다만 위 해결방법은 좋지 못한 해결법일 수도 있는데 payload를 줄이는 것을 먼저 검토해보는 것이 더 이상적일 것 같다라는 생각이다.
NBL 설정시 enable_cross_zone_load_balancing 이슈
패킷 덤프를 통해 확인하는 ALB와 NLB의 차이점 (2) - NLB 동작 원리 글을 읽던 중 enable_cross_zone_load_balancing옵션을 true로 설정하지 않으면 다른 AZ에 있는 NLB로 요청이 가는 경우 트래픽이 전달되지 않는 이슈를 겪을 수 있다는 내용을 보게 되었다. 이런 설정 관련 이슈는 문제가 생겼을 때 원인파악이 쉽지 않을 수 있으므로 알아두면 좋을 것 같다.
jhipster
jhipster는 간단한 CLI를 통해서 웹 어플리케이션에 필요한 기본 구성요소를 갖춘 Spring 기반 프로젝트를 생성해주는 플랫폼이다.
어떻게 생성되나 궁금해서 만들어 봣는데 생성되는 파일이 어마어마 하다. (샘플 프로젝트 저장소 참고)
초기 스타트업에서 어느정도 갖추어진 웹 어플리케이션을 빠르게 만들어서 런칭하고자 하는 경우 괜찮아 보인다. 다만 메니페스토 파일들이 상당히 많아 아키텍쳐를 내 입맛대로 구성하기에는 조금 어렵다는 문제가 있다. 그리고 테스트 도구로 JUnit만 지원하는 부분도 조금 아쉽다. 제 만약 JWT나 Cache등 설정을 처음하면서 에시자료로 참고하기에는 좋아보인다.
코틀린도 jhipster가 있지 않을까 찾아봤는데 역시나 존재했다. jhipster-kotlin
validation 관련해서 좋은 글
validation과 관련해서 좋은 글이 있어 소개해 본다. https://ducmanhphan.github.io/2019-12-22-Clean-code-with-validate-input/
Javascript로 소개된 내용이라 JS와 관련된 내용이 있지만… 아무튼, 내용을 요약하면 아래와 같다.
- 빨리 실패하고 반환해라
- null 체크 시 여러개의 인수가 있다면 짧게 사용하기 위해 노력하라
- 숫자 유효성 검사 시 유효성 범위를 잘 파악해라
- 문자열 검증에 필요한 일반적인 함수를 만들어 사용하라
- 잘못된 값이 전파되지 않도록 주의하라
- 올바른 예외를 선택하라
- 매직넘버를 반환하지 마라
- 불변 변수를 사용하라
- 메소드의 부작용을 최소화 하라
- 정적 분석 도구를 사용하라
ULID
ULID는 UUID와 같이 중복이 거의 생기지 않는 식별자를 제공하면서 순서까지 보장해 줄 수 있는 정렬가능한 식별자이다.
Database의 식별자로 UUID를 사용하다보면 유일성을 보장해주기 때문에 마이그레이션 이슈나 Long값을 ID로 사용 시 발생하는 최대값 문제 등이 발생하지 않는 장점이 있다. 하지만 값에 대한 정렬을 보장하지 않기 때문에 따로 등록일시에 인덱스를 준다던지 하는 비효율이 발생한다.
이에 대한 대안으로 ULID를 사용할 수 있는데 문자열 뿐만 아니라 UUID 값에 대한 순서도 보장해줘서 UUID컬럼을 대체하기에도 아주 좋다.
list = ['01FDCRJSTF353T4XKT312HAKJC',
... '01FDCRK2F9RP4GCV9ZTMBW0M4D',
... '01FDCRJAJKY2A40QP6A29A6ZWG',
... '01FDCRKBCHE02QPSGDDND3TAX2']
>>> list
['01FDCRJSTF353T4XKT312HAKJC', '01FDCRK2F9RP4GCV9ZTMBW0M4D', '01FDCRJAJKY2A40QP6A29A6ZWG', '01FDCRKBCHE02QPSGDDND3TAX2']
>>> list.sort()
>>> list
['01FDCRJAJKY2A40QP6A29A6ZWG', '01FDCRJSTF353T4XKT312HAKJC', '01FDCRK2F9RP4GCV9ZTMBW0M4D', '01FDCRKBCHE02QPSGDDND3TAX2']
>>> v1 = ulid.new().uuid
>>> v2 = ulid.new().uuid
>>> v3 = ulid.new().uuid
>>> v4 = ulid.new().uuid
>>> list = [v4, v3, v1, v2]
>>> list
[UUID('017bda50-31db-8e9a-95d7-7656f03a03cb'), UUID('017bda50-224d-2400-7347-da0fb8576913'), UUID('017bda4f-f388-f103-e15c-7c9ffc3d4cfb'), UUID('017bda50-1330-4921-be3f-6115235517f4')]
>>> sorted(list)
[UUID('017bda4f-f388-f103-e15c-7c9ffc3d4cfb'), UUID('017bda50-1330-4921-be3f-6115235517f4'), UUID('017bda50-224d-2400-7347-da0fb8576913'), UUID('017bda50-31db-8e9a-95d7-7656f03a03cb')]
github autolinks
Github에서 Configuring autolinks to reference external resources 기능을 제공해준다.
이 기능은 PR의 본문 내(다른 곳에서 링크가 달리는지는 확인해 보지 못했다.) 조건에 맞는 문구를 입력하면 자동으로 Link를 달아주는 기능이다.JIRA의 티켓 링크와 같은 곳에 사용하면 좋다.
flasgger
Flask에서 Swagger로 사용할만한 것들이 뭐가 있는지 찾아보다가 그나마 사용성이 좋고 저장소의 스타수가 많은 것이 바로 flasgger이다.
Spring의 Swagger보다는 다소 해줘야 하는게 많지만(Spring에서는 의존성만 추가하면 문서를 기본값으로 만들어준다) DOC에 적는 방법은 나쁘지 않은 방법이다. 어차피 DOC문서에 설명을 적는 경우가 많으므로…
# 설정
swagger_template = {
"securityDefinitions": {"APIKeyHeader": {"type": "apiKey", "name": "Authorization", "in": "header"}}
}
Swagger(app, template=swagger_template)
# API
def contact_vendor(token: dict) -> tp.Tuple[Response, int]:
"""거래처 컨택 액션 히스토리를 저장합니다.
---
tags:
- contact
parameters:
- name: Request
in: body
schema:
type: object
required:
- vendor_id
- contact_type
properties:
vendor_id:
type: string
format: uuid
description: 거래처 ID
contact_type:
type: string
enum: ['CALL_DIRECTLY', 'CONSULT_REQUEST', 'SEND_KAKAO_TALK']
description: 유형
security:
- APIKeyHeader: ['Authorization']
responses:
201:
description: Created
400:
description: Bad Request
401:
description: Unauthorized
404:
description: Not Found
"""
# 코드 생략...
Elastic 가이드 북
최근 Elastic Search와 관련하여 이슈를 겪으면서 공부해야겠다고 생각했는데 한글로된 Elastic 가이드북이 있어서 적어본다. 공부하자…
Postgresql Autovacuum
현재 스포카에서는 주 DB로 PostgreSQL을 사용한다. 최근에 포인트팀에서 PostgreSQL의 vacuum 이슈가 있었고 관련해서 읽어보면 좋은 글을 소개해 주어서 적어본다. PostgreSQL 튜닝 - Autovacuum 최적화에 대하여
AWS Health Dashboard
최근 AWS 한국 리전의 서비스 상태가 썩 좋지 않은것 같다. S3 이미지 로딩 속도도 느리고(CloudFront로 바꿔야 하는데…) AWS 콘솔의 응답 시간도 예전보다 느려진것 처럼 느껴진다. 운영팀에서도 서버가 느려졌다고 하는데 서버의 상태를 보면 아주 양호한것을 볼 수 있었다. AWS Health Dashboard를 보아도 문제는 없어보이는데 아무튼 주기적으로 모니터링을 해야겠다.
Null object pattern
동료가 디자인 패턴 중 Null object pattern 이 있다는 것을 소개시켜 주었다.
Null 값이 있으면 default로 특정한 값을 반환하게 하는 패턴은 익숙하게 사용하고 있었는데 디자인 패턴 이름이 있는지는 처음 알게 되었다.
Test 안티 패턴
코드리뷰를 하면서 테스트 코드의 안티패턴 사례를 알려주기 위해 글을 찾던 중 Stackoverflow의 Unit testing Anti-patterns catalogue 글을 발견하게 되었다. 좋은 내용이 많아서 블로그에 번역과 함께 예시를 적은 글을 써봐야겠다.
Key Kubernetes Concepts
쿠버네티스를 처음 접한다면 Key Kubernetes Concepts 글을 읽어두면 좋을 것 같아서 적어둔다. 인프라는 언제나 봐도 어렵다.