
2021년 11월 개발일지
11월은 회사 내 이벤트가 많은 한달이었다.
먼저, 사무실을 이사했다. 새로운 사무실에 출근하니 아래 사진처럼 예쁜 로비가 반겨 주어서 새 회사 출근하는 것 같은 기분이 들었다.

아무래도 내가 역마살이 낀게 분명해 보인다. 지금 회사에서도 입사 후 10개월만에 가까운 곳이긴 하지만 새 사무실로 이사를 하게 되었다. 기존에 다녔던 회사들도 근속년수에 상관없이 거의 1년에 한번씩은 이사 또는 합병등으로 사무실을 옮겨다녔던 것 같다. 이제 그만 옮겨다닐때도 된거 같은데…^^;;
두번째로 타팀의 인수 소식이었다. 옆에 팀이 운영하는 서비스를 다른 회사에서 인수하게 되었다는 소식을 듣게 되었다. 얼마전부터 투자를 위한 준비를 하고 있다는 소식을 들었었는데 갑작스런 인수 소식에 적잖게 놀랐었다. 아쉬운 부분은 외부 뉴스를 통해 이 사실을 알게 되었다는 것인데 경영진도 뉴스가 이렇게 나가게 될줄은 몰랐던 것 같다.
세번째로 팀내 정비기간을 가지게 되었다. 정비기간에 백엔드는 언어전환을 하기로 결정하였다. 사실 언어에 대한 전환은 이전부터 이야기해왔었는데 감사하게도 정비기간을 가지면서 언어 전환을 할 수 있도록 배려해주셨다. 언어 전환에 대한 준비는 충분하지 않지만 그동안 준비는 어느정도 해왔었고 지금 하지 않으면 나중에는 더이상 기회가 없을 수도 있으니 잘 준비해서 전환을 성공적으로 마무리 했으면 한다.
아래는 11월동안 정리한 이슈 내용들이다.
N + 1
QA기간 중 기존에 만들어진 광고 거래처 조회 기능의 응답속도가 느리다라는 이슈를 보고받았다. 페이징 처리가 되어있어서 조회 건수에 대한 이슈는 아닌듯 하여 쿼리 로그를 좀 뜯어보니 N + 1 이슈였다.
광고 거래처는 기존에 만들어둔 거래처와 여러 관련 테이블들의 관계가 맺어져 있다. 그러다 보니 제휴 거래처 조회시 다른 여러 테이블들을 조회하려고 해서 N + 1 문제가 발생하는 것이다.
SQL Alchemy도 N + 1문제를 해결하기 위해서 joinedload라는 구문을 제공해준다. QueryDSL의 fetchJoin과 비슷하다고 보면 되겠다.
변경전과 변경 후 쿼리를 보면 확연히 요청 수가 줄어든 것을 볼 수 있다.
변경 전
SELECT * FROM advertisement_vendor JOIN partner_vendor ON partner_vendor.id = advertisement_vendor.partner_vendor_id
SELECT * FROM vendor WHERE vendor.id = %(param_1)s
SELECT * FROM partner_vendor WHERE partner_vendor.id = %(param_1)s
SELECT * FROM partner_vendor_tag, partner_vendor_tag_assoc WHERE %(param_1)s = partner_vendor_tag_assoc.partner_vendor_id AND partner_vendor_tag.id = partner_vendor_tag_assoc.partner_vendor_tag_id
SELECT * FROM partner_vendor WHERE partner_vendor.id = %(param_1)s
SELECT * FROM partner_vendor_tag, partner_vendor_tag_assoc WHERE %(param_1)s = partner_vendor_tag_assoc.partner_vendor_id AND partner_vendor_tag.id = partner_vendor_tag_assoc.partner_vendor_tag_id
SELECT * FROM partner_vendor WHERE partner_vendor.id = %(param_1)s
SELECT * FROM partner_vendor_tag, partner_vendor_tag_assoc WHERE %(param_1)s = partner_vendor_tag_assoc.partner_vendor_id AND partner_vendor_tag.id = partner_vendor_tag_assoc.partner_vendor_tag_id
SELECT * FROM partner_vendor WHERE partner_vendor.id = %(param_1)s
SELECT * FROM partner_vendor_tag, partner_vendor_tag_assoc WHERE %(param_1)s = partner_vendor_tag_assoc.partner_vendor_id AND partner_vendor_tag.id = partner_vendor_tag_assoc.partner_vendor_tag_id
변경 후
SELECT * FROM advertisement_vendor JOIN partner_vendor ON partner_vendor.id = advertisement_vendor.partner_vendor_id LEFT OUTER JOIN partner_vendor AS partner_vendor_1 ON partner_vendor_1.id = advertisement_vendor.partner_vendor_id LEFT OUTER JOIN vendor AS vendor_1 ON vendor_1.id = partner_vendor_1.vendor_id
SELECT * FROM partner_vendor_tag, partner_vendor_tag_assoc WHERE %(param_1)s = partner_vendor_tag_assoc.partner_vendor_id AND partner_vendor_tag.id = partner_vendor_tag_assoc.partner_vendor_tag_id
SELECT * FROM partner_vendor_tag, partner_vendor_tag_assoc WHERE %(param_1)s = partner_vendor_tag_assoc.partner_vendor_id AND partner_vendor_tag.id = partner_vendor_tag_assoc.partner_vendor_tag_id
SELECT * FROM partner_vendor_tag, partner_vendor_tag_assoc WHERE %(param_1)s = partner_vendor_tag_assoc.partner_vendor_id AND partner_vendor_tag.id = partner_vendor_tag_assoc.partner_vendor_tag_id
SELECT * FROM partner_vendor_tag, partner_vendor_tag_assoc WHERE %(param_1)s = partner_vendor_tag_assoc.partner_vendor_id AND partner_vendor_tag.id = partner_vendor_tag_assoc.partner_vendor_tag_id
Kotlin JPA에서 연관관계 매핑시 immutable하게 하는 방법
이전에도 얘기했었지만 JPA의 Entity는 기본적으로 mutable한 필드를 전제로한다. kotlin을 사용하면서 immutable한 필드를 자주 활용하는데 Entity도 immutable한 필드를 사용하면 좋지 않을까라는 고민을 자주하곤 한다.
backing property를 활용하면 immutable한 필드를 사용할 수 있다.
@Entity
data class OrderEntity(
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
val id: Long? = -1,
val firstName: String,
val lastName: String
) {
@OneToMany(cascade = [(CascadeType.ALL)], fetch = FetchType.LAZY, mappedBy = "order")
private val _lineItems = mutableListOf<LineItem>()
@Transient
val lineItems = _lineItems.toList()
fun addLineItem(newItem: LineItem) = this._lineItems.plusAssign(newItem)
}
JDK 17
프로젝트를 세팅하면서 JDK 17을 기반으로 Kotlin 프로젝트를 설정하였는데 아래와 같이 컴파일 오류가 발생하였다.

위 내용은 2021년 10월 15일에 기록한 것인데 2021년 12월인 현재는 JDK 17로 변경한 후 컴파일 해도 정상적으로 수행된다.
devopsart
Terraform을 이용한 AWS 리소스 관리 방법을 가이드해주는 페이지가 있어서 기록해본다.
https://terraform101.inflearn.devopsart.dev/intro/
Elasticsearch Wildcard query
Elasticsearch에도 RDBMS의 like절과 유사한 wildcart query를 제공해준다.
GET /_search
{
"query": {
"wildcard": {
"user.id": {
"value": "ki*y",
"boost": 1.0,
"rewrite": "constant_score"
}
}
}
}
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-wildcard-query.html
Intellij Regex로 치환하기
코드를 일괄적으로 변경해줘야할 때 아래와 같이 동일한 구문에 일부만 다른 문자를 가진 구문을 변경해줘야 할 때가 있다.
map.getFirst("test")를map.["test"]로 변경해주세요.
문제는 test라는 글자만 들어가 있는 것이 아니라 example, sample 등과 같이 다른 문자열을 포함한 구문을 모두 바꿔줘야한다는 것이다.
이럴때 아래와 같이 입력해주면 손쉽게 바꿀 수 있다.
\.getFirst\((.*)\)
[$1]
캐시 퇴거 전략
Redis 사용시 아래와 같은 퇴거전략을 선택하여 사용할 수 있다. 내가 사용하는 캐시서버의 기본 퇴거전략을 꼭 살펴보고 설정하도록 하자. 참고로 no-eviction는 선택하지말자………
no-eviction
기존 데이터 삭제 안함. 메모리 한계에 도달하면 OOM 오류 반환하며 새 데이터가 저장되지 않는다.
allkeys-lru
LRU로 삭제하여 공간확보하고 새 데이터 저장
volatile-lru
expire set을 가진 것 중 LRU로 삭제하여 공간확보하고 새 데이터 저장
allkeys-random
랜덤으로 삭제하여 공간확보하고 새 데이터 저장
volatile-random
expire set을 가진 것 중에서 랜덤으로 삭제하여 공간확보하고 새 데이터 저장
volatile-ttl
expire set을 가진 것 중 TTL이 짧은 것부터 삭제하여 공간확보하고 새 데이터 저장
https://zetawiki.com/wiki/%EB%A0%88%EB%94%94%EC%8A%A4_maxmemory-policy
kULID 동시성 이슈
kotlin ULID random 함수 사용시 시간생성을 System.currentTimeMillis()를 사용한다. 그러다보니 배열을 통한 다수의 random 함수 사용시 정렬을 보장하지 않느 문제가 있다.
System.nanoTime()을 사용한다면 해결할 수 있을 것 처럼 보이나 이마저도 ULID의 길이 정책때문에 쉽게 해결할 수 없어보인다.
관련해서 이슈 제기를 하였지만 한달이 다되어가는 지금까지도 답변이 없는걸 보니 프로젝트 운영을 하지 않는게 아닐까 싶다…
다행히 ulid-creator는 위 문제를 어느정도 보완한 Monotonic ULID를 지원해준다.
다만, synchronized를 이용해서 동일한 ULID가 생성되지 않도록 제어를 하는 것이기 때문에 scale-out된 서버에서 동시에 생성하였을 때 ULID가 겹칠 가능성은 여전히 가지고 있다. 하지만 다른 서버에서 생기는 ULID는 time 구간 외 random 구간에서 겹칠 가능성이 낮으므로 무시해도 되지 않을까 싶다.
JPA JSONB 타입 사용하기
JPA에서 Postgresql의 JSONB 타입을 사용하려면 아래와 같이 TypeDef나 Type을 사용해야 한다.
@TypeDefs(
TypeDef(name = "jsonb", typeClass = JsonBinaryType::class)
)
@Entity
class Sample
@Type(type = "jsonb")
@Column(name = "attribute")
val attributes: List<Attribute>
다만, 해당 어노테이션들은 Deprecated되었다. hibernate 6.0부터는 사용되지 않을거라고 하는데…언제쯤 나올지 모르겠다.
그나저나 deprecated되어서 IDEA에서 줄 그어지는거 너무 불편하네 ㅠㅠ
Plural form of TypeDef.
Deprecated
6.0 will introduce a new series of type-safe annotations to serve the same purpose
Author:
Emmanuel Bernard, Steve Ebersole
TestContainer
언어전환을 하면서 SQL Alchemy로 정의되어 있는 Entity를 JPA로 표현할 때 잘못표현된게 있지 않을 지 검증할 필요가 있었다. 그러다보니 테스트시 손쉬운 방법인 H2를 이용한 인메모리 환경으로 테스트하기는 어려워 보였다.
그래서 기존의 DDL을 flyway를 이용해 생성하고 Entity 정의가 잘 되었는지 확인하기 위해서 TestContainer를 활용하기로 하였다.
Elasticsearch도 사용중인데 이를 이용한 테스트 환경 구성도 TestContainer를 사용할 수 있으니 좋은 선택이었던 것 같다.
다만 테스트 시 조금 오래 걸리는 문제가 있는데 이부분은 차차 개선해가면 좋을 것 같다.
JPA Test with TestContainer
TestContainer를 이용하여 DataJpaTest할때 인메모리를 사용하지 않도록 하기 위해서는 아래와 같이 설정해줘야 한다.
@DataJpaTest
@AutoConfigureTestDatabase(replace = AutoConfigureTestDatabase.Replace.NONE)
@Import(TestDatabaseConfiguration::class)
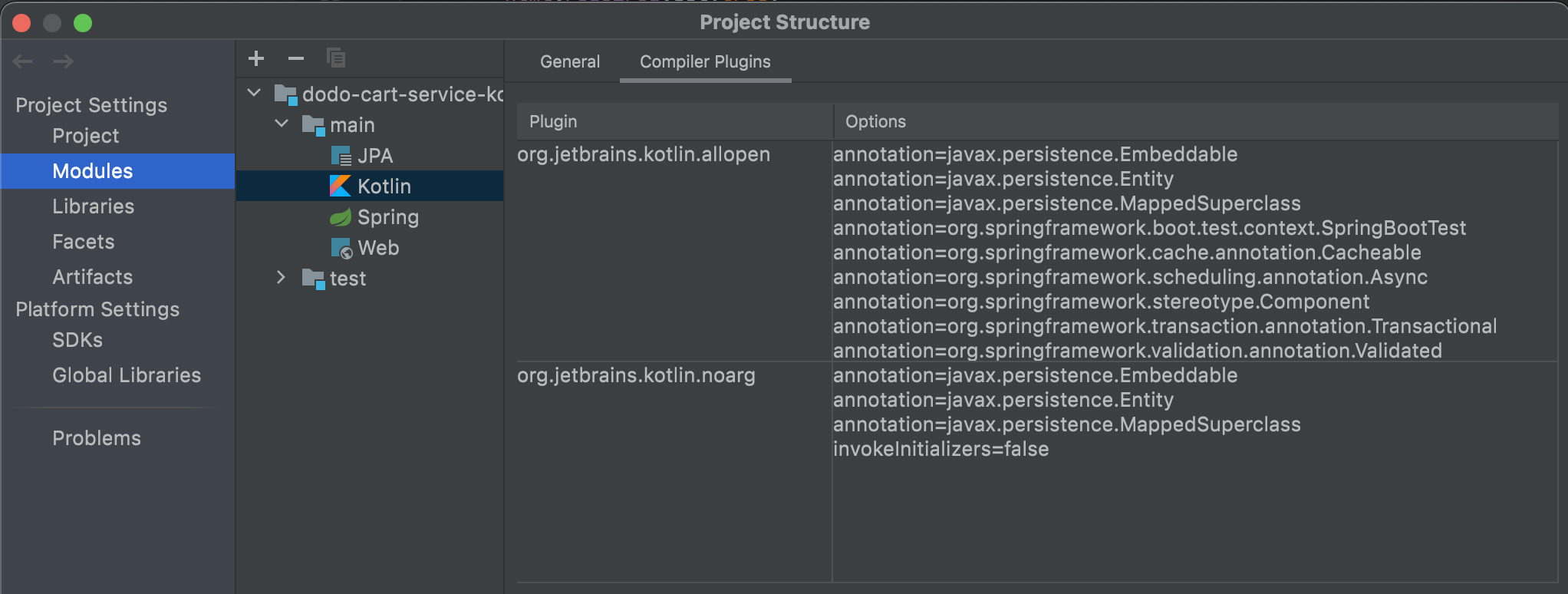
Intellij 플러그인 설치목록 확인
Intellij Project Struecture에서는 플러그인 설치 목록을 볼 수 있다.
Property 란
우아한 테크의 어디 가서 코프링 매우 알은 체하기!에서 Property에 대한 정의를 알려주어서 적어본다.
Property = getter + setter + field
즉, 우리가 Class 내에 정의한 속성, 값 등으로 불리는 것은 field이고 이 field가 getter와 setter를 외부로 노출한다면 property라고 할 수 있다는 것이다.
no-arg plugin
kotlin으로 SpringBoot 세팅을 할때 JPA를 사용하려면 JPA 플러그인을 추가해주어야 한다.
plugins {
// 생략...
kotlin("plugin.jpa") version "1.6.0"
}
해당 플러그인 내에는 no-arg플러그인을 포함하고 있고 @Entity, @Embeddable, @MappedSuperclass에 대한 설정을 기본적으로 제공하기 때문에 별도로 no-arg 설정을 추가해주지 않아도 된다.