
2023년 2월 개발일지
말도 많고 탈도 많았던 새로운 근무제도가 2월부터 실행되었다. 다만 제품팀에서 반발이 심했기에 유연근무 시간에 대해서는 2월동안 지켜보며 조정을 하기로 합의를 보았다. 유연근무제에 대한 반발이 더 심했기에 재택근무 방식에 대해서는 조정기간을 따로 주지 않았다. 2월 말에 유연근무 시간은 조정이 되어 기존에 10시~17시 코어 근무시간을 가지도록 하는 방법에서 11시~17시 코어 근무시간을 가지도록 하는 것으로 바뀌었다. 사실 유연근무 시간이 조정되어서 그나마 다행이었지만 따지고 보면 우리팀은 기존에 바뀐게 없고 재택근무만 주 2회에서 월 2회로 줄어든 꼴이 되어버렸다. 여전히 불만스럽지만 어쩌겠는가. 회사가 까라면 까야지.
1월에 새 자전거를 사고 날씨가 추워 한번도 자전거를 타지 못했다. 그래서 2월에 날씨가 풀리기만을 기대했는데 2월 중순부터 점점 날씨가 따뜻해지기 시작해서 자전거를 타고 출근을할 계획을 하였다. 집에서 회사까지 지하철로 40분 정도 걸리는데 자전거로 가도 40분 정도면 충분히 도착하는 거리라 비가 오거나 약속이 있는날이 아니면 무리없이 자출을 할 수 있다고 생각했다.
이전에는 저렴한 자전거였고 피팅에 대한 필요성을 느끼지 못해 받지 않았는데, 작년에 국토종주를 다녀오며 자전거 피팅의 중요성을 깨달은 터라 이번에 자전거도 새로 장만했겠다 자주가던 자전거 가게에서 피팅을 받아보기로 하였다. 단순 기본 피팅이라 센서를 통해서 피팅을 봐주는건 아니었고 안장 높이라던지 자세등을 교정 받았다. 하는김에 클릿도 오래되어서 함께 바꿔주면서 클릿 위치도 교정받았다.
기존보다 더 좋은 자전거를 타려다보니 왠지 그에 걸맞는 옷을 장만하고 싶어져서 자전거 의류에서부터 헬멧, 물통 등등 이것저것 자전거 용품을 구매하게 되었다. 자전거 운동은 간지(?)가 생명이다보니 기왕이면 이쁜거, 좋은거를 사고 싶은게 사람의 욕심인지라 예상보다 많은 지출을 하게 되었다. 지갑은 가벼워졌지만 새로산것들을 장착(?)하고 달릴 생각하니 오랜만에 설렜다.
회사 디자이너분의 지인 요청으로 JIRA 관련해서 외부에 사용사례를 알려주는 미팅을 가지게 되었다. 사내 블로그에 스포카에서 Jira를 활용하여 프로젝트를 수행하는 방법이라는 글을 올렸었는데 이 글을 보고 자신들의 팀에 JIRA를 도입할 때 참고할만한 여러가지 조언들을 얻기 위해서였다. 사실 우리팀도 이상적인 애자일 개발방법을 수행하고 있다고 하기 힘들고 JIRA도 모두가 잘 활용하고 있다고 보기 힘들지만 내가 생각하는 현실적인 이야기를 해주었다.
JIRA는 조직에서 프로젝트를 좀더 원활하게 수행하고 손쉽게 피드백을 받을 수 있도록 도와주는 도구에 불과하다고 생각한다. 즉, 이 도구가 팀의 생산성을 방해하는 요소로 작용해서는 안된다는게 나의 생각이다. 조직이 좀 더 생산적이고 잘 성장할 수 있는 방법을 찾아가는데 집중하고 이 과정에 JIRA를 잘 활용할 수 있는 방법을 고민하는게 좋다고 생각한다. 이러한 나의 생각이 미팅에 참가하셨던 분들께 잘 전달되었으면 한다.
올해는 2월에 연봉협상을 진행했다. 사실 작년 연봉협상 때에는 경기가 나빠지기 전이었고 총알이 막 장전되었던 시기라 대부분이 만족스러운 연봉협상결과를 얻었지만 올해는 경기가 좋지 않아 많은 스타트업들이 문을 닫거나 구조조정을 하는 상황이라 큰기대를 하기는 어려웠다. 인사평가는 높게 받았지만 역시나 경기의 영향이었을까 내가 생각했던 인상폭의 최소한의 요건에도 부합하지 못했다. 좀 더 어필을 해서 조정을 시도해볼 수 있었겠지만 큰 기대를 하지 않아서인지 그대로 협상을 마무리 지었다. 작년에는 회사가 나를 믿어주었지만 올해는 나의 차례지 않을까 생각한다. 올해는 비록 아쉬움만 남은 연봉협상이지만 내년에는 좀 더 나은 결과를 얻을 수 있기를 기대해본다.
아래는 2월동안 정리한 이슈 내용들이다.
JPA에서 Transaction내 쿼리 실행 순서
아래와 같이 하나의 Transaction 내에서 원하는데이터를 지운 후 다시 저장하도록 하는 코드를 작성하였는데, 오류가 발생하는 이슈를 겪었다.
@Transactional
fun write(results: List<PaymentTransactionComparisonResult>): Reconciliation {
val transactionDate = getTransactionDate(results.first())
reconciliationRepository.deleteByTransactionDate(transactionDate)
val reconciliation = Reconciliation(transactionDate) { results.map { t -> t.toComparedTransaction(it) } }
return reconciliationRepository.save(reconciliation)
}
ERROR: duplicate key value violates unique constraint "reconciliation_transaction_date_uk"
Detail: Key (transaction_date)=(2023-02-01) already exists.
거래일에 Unique Key가 설정되어 있는 Reconciliaiton 테이블에 동일한 거래일을 가진 Entity를 영속화 하려고 시도하다가 발생한것이 었다. 하지만 이상했다 분명 코드를 보면 동일한 거래일을 가진 모든 Reconciliation을 지우고 해당 거래일을 가진 Reconciliation을 생성한 후 저장을 하기 때문이다.
원인은 JPA의 Flush 정책 때문이었다. JPA의 Flush 이벤트를 실행하는 구현체인 AbstractFlushingEventListener.performExecutions를 보면 아래와 같이 정의되어 있다.
Execute all SQL (and second-level cache updates) in a special order so that foreign-key constraints cannot be violated:
- Inserts, in the order they were performed
- Updates
- Deletion of collection elements
- Insertion of collection elements
- Deletes, in the order they were performed
즉, 삭제 함수가 저장 함수보다 먼저 정의되어 있어도 결국 삭제함수는 가장 마지막에 실행된다는 것이다. 그러니 거래일에 Unique Key가 걸려있는 Reconciliation Table에 동일한 거래일을 가진 Entity가 저장되려고 하니 오류가 발생하는 것이었다.
그렇다면 이 문제를 어떻게 해결할 수 있을까?
Unique Key 제거
코드를 더럽히지(?) 않고 가장 손쉽게 해결할 수 있는 방법은 Unique Key를 제거하는 것이다. 그렇다면 Insert가 아무리 먼저 실행이 되더라도 Unique Key 제약조건 오류가 발생하지 않을 것이기 때문이다. 하지만 이런 방법은 좋은 해결방법이라 할 수 없다. 영속화의 제약조건을 설정하지 않는다면 아래와 같이 조회 시 매번 조건을 체크하는 등의 불필요한 로직을 수반하기 때문이다.
- Unique Key가 설정되어 있다면
class ReconciliationRepository { fun findReconciliationByTransactionDate(transactionDate: LocalDate): Optional<Reconciliation> { // 구현코드... } } class FooService(private val reconciliationRepository: ReconciliationRepository) { fun getReconciliation(transactionDate: LocalDate): Reconciliation { return reconciliationRepository.findReconciliationByTransactionDate(transactionDate).orElseThrow() } } - Unique Key가 설정되어 있지 않다면
class ReconciliationRepository { fun findReconciliationByTransactionDate(transactionDate: LocalDate): List<Reconciliation> { // 구현코드... } } class FooService(private val reconciliationRepository: ReconciliationRepository) { fun getReconciliation(transactionDate: LocalDate): Reconciliation { val reconciliations = reconciliationRepository.findReconciliationByTransactionDate(transactionDate) if (reconciliations.isEmpty()) throw Exception() if (reconciliations.size > 1) throw Exception() return reconciliations.first() } }
한편, reconciliationRepository.deleteByTransactionDate(transactionDate)가 마지막에 실행 된다면 Insert된 데이터도 삭제되지 않을까 우려할 수도 있다. JPA는 이러한 문제를 해결하기 위해서 Insert 전에 Select를 먼저 실행한다. 그런다음 이미 영속화 되어 있는 Entity들의 ID를 순회하면 삭제를 하기 때문에 조회 이후에 생성된 Entity는 삭제되지 않는다.
@Modifying 활용
Spring Data JPA에서는 @Modifying을 통해 Native Query를 직접 실행할 수 있도록 지원하고 있다. 그래서 ReconciliationRepository.deleteByTransactionDate 함수를 아래와 같이 재정의할 수 있다.
@Modifying
@Query("delete from Reconciliation r where r.transactionDate = :transactionDate")
fun deleteByTransactionDate(transactionDate: LocalDate)
이렇게하면 JPA의 Flush 실행 규칙과는 무관하게 삭제쿼리가 먼저 실행되는것을 볼 수 있다. 하지만 이러한 방법도 이슈가 존재한다. 바로 JPA에서 실행되는 Cascade가 실행되지 않는다는 것이다. JPA의 Cascade는 비록 암묵적이긴하나 Entity 관계들의 영속화를 일일이 다루지 않아도 되기 때문에 상당한 코드를 줄일 수 있다는 장점이 있다. 즉 Native Query의 사용은 이러한 JPA의 장점을 가져가지 못한다는 것이다.
EntityManger.flush 활용
다른 또하나의 방법은 바로 EntityManager의 Flush를 활용하는 것이다. Transaction이 끝나면서 AbstractFlushingEventListener가 Flush 이벤트를 수신하기전에 EntityManager로 Flush를 강제로 실행히켜서 쿼리가 먼저 실행되도록 해버리는 것이다.
@Transactional
fun write(results: List<PaymentTransactionComparisonResult>): Reconciliation {
val transactionDate = getTransactionDate(results.first())
reconciliationRepository.deleteByTransactionDate(transactionDate)
entityManager.flush()
val reconciliation = Reconciliation(transactionDate) { results.map { t -> t.toComparedTransaction(it) } }
return reconciliationRepository.save(reconciliation)
}
이렇게하면 앞선 두 해결방법의 문제점은 해결할 수 있다. Service 코드에 영속화와 관련한 코드가 숨어 있다. 즉, Repository의 책임을 Service 코드에 전가시키는 것이다. 거기다 entityManager.flush()는 코드의 순서가 중요하다. 누군가가 실수로 해당 코드의 위치를 옮겨버린다면 심각한 오류가 발생할 수 있다. 다만 이 위험성은 아래와 같이 테스트 코드를 통해 커버할 수 있다.
test("성공한 거래 비교 결과가 주어지면 거래일 기준 기존 대사결과를 삭제하고 성공한 대사 결과를 저장한다.") {
// Given
// 생략...
// When
val actual = reconciliationWriter.write(transactionDate, results)
// Then
verifySequence {
reconciliationRepository.deleteByTransactionDate(LocalDate.of(2023, 1, 9))
entityManager.flush()
// ...생략
}
}
위 방법 중 나의 선택은 세번째이다. 첫번째와 두번째의 문제점이 더 나쁘다고 생각했기 때문이다. 하지만 세번째도 여전히 문제점을 가지고 있기에 이상적인 해결방법이라고 할 수 없어 아쉬운 마음이다. 더 좋은 방법이 없을까?
docusaurus
docusaurus는 jekyll과 같이 Markdown 기반으로 홈페이지를 구성할 수 있도록 도와주는 도구이다. 이름에서 유추할 수 있다시피 블로그와 같은 목적보다는 문서를 위한 페이지를 구성할 때 좀 더 유용해 보인다.
JVM 메모리 이해와 케이스 스터디
JVM 메모리 이해와 케이스 스터디라는 글을 우연히 읽게 되었다. 삼성 SDS에서 작성한 글인데, JVM에 대한 이해와 깊이를 엿볼 수 있는 글이다. 최근 OOM이슈를 몇번 겪으면서 메모리 관리에 대한 지식을 좀 더 쌓을 필요가 있다는 생각을 하게된다.
‘좋은 설계’의 조건
우연히 소프트웨어 설계 20년 해보고 깨달은 ‘좋은 설계’의 조건을 읽게 되었다. ‘좋은 설계’에 대한 고민거리가 많은 요즘 참 재미있게 읽었던 것 같다. 그 중 가장 기억에 남는 문구를 적어본다.
설득 또한 설계의 일부다.
간단한 HTTP 서버 띄우는 법
Shell 스크립트를 통해 간단한 HTTP 서버를 띄우는 방법을 적어본다. 아래 스크립트를 작성하고 실행하면 된다.
#!/usr/bin/env bash
RESPONSE="HTTP/1.1 200 OK\r\nConnection: keep-alive\r\n\r\n${2:-"OK"}\r\n"
while { echo -en "$RESPONSE"; } | nc -l "${1:-8080}"; do
echo "================================================"
done
출처: https://github.com/benrady/shinatra/blob/master/shinatra.sh
mockk의 verifyOrder와 verifySequence의 차이점
단위테스트를 수행할 때 앞에서 다루었던 JPA에서 Transaction내 쿼리 실행 순서에서 볼 수 있다시피 코드의 실행순서를 검증해야할 때가 있다. Mockk을 사용한다면 verifyOrder와 verifySequence를 사용해서 코드의 실행순서를 검증할 수 있다.
여기서 실행순서를 검증하는 것이라면 verifyOrder와 verifySequence를 굳이 두개의 함수로 나눌 필요가 왜 있을까 궁금할 것이다. 두 함수의 차이는 아래와 같다.
-
verifyOrder지정된 호출을 일부만 순서대로 실행했는지 검증한다. -
verifySequence지정된 호출을 모두 순서대로 실행했는지 검증한다.
설명으로는 이해하기 쉽지 않으니 Mockk의 공식 홈페이지에서 제공하는 예제코드를 살펴보자.
class MockedClass {
fun sum(a: Int, b: Int) = a + b
}
val obj = mockk<MockedClass>()
val slot = slot<Int>()
every {
obj.sum(any(), capture(slot))
} answers {
1 + firstArg<Int>() + slot.captured
}
obj.sum(1, 2) // returns 4
obj.sum(1, 3) // returns 5
obj.sum(2, 2) // returns 5
verifyOrder는 지정된 호출을 모두 호출해도 혹은 일부만 호출해도 순서만 지켜진다면 성공한다.
verifyOrder {
obj.sum(1, 2)
obj.sum(2, 2)
}
verifyOrder {
obj.sum(1, 2)
obj.sum(1, 3)
obj.sum(2, 2)
}
verifySequence는 지정된 호출을 모두 순서대로 호출해야지만 성공한다.
verifySequence {
obj.sum(1, 2)
obj.sum(1, 3)
obj.sum(2, 2)
}
// 실패!!
verifySequence {
obj.sum(1, 2)
obj.sum(2, 2)
}
ManyToMany에서 원본 데이터 삭제 이슈
JPA에서 관계테이블을 활용한 N:M 관계를 표현할 때 @ManyToMany를 사용한다면 조심해야할 부분이 바로 Cascade이다. 이번에 정산 Entity를 정의하면서 아래와 같이 연관관계를 설정하였는데 CascadeType.ALL을 설정하면서 의도치 않게 거래내역까지 삭제하는 실수를 범하였다.
@ManyToMany(cascade = [CascadeType.ALL])
@JoinTable(
name = "vendor_settlement_payment_assoc",
joinColumns = [JoinColumn(name = "vendor_settlement_id")],
inverseJoinColumns = [JoinColumn(name = "payment_id")],
)
val payments: List<Payment> = payments.sortedByDescending { it.paidAt }
@OneToMany와 @ManyToOne을 통해 N:M관계를 표현해 주는것이 익숙했던 터라 CascadeType.ALL을 사용해도 단순히 관계 테이블만 삭제할거라 생각했던것이 문제였다.
위 문제를 해결하려면 아래와 같이 CascadeType.REMOVE를 제외하면 된다.
@ManyToMany(cascade = [CascadeType.REFRESH, CascadeType.MERGE, CascadeType.REFRESH, CascadeType.DETACH])
@JoinTable(
name = "vendor_settlement_payment_assoc",
joinColumns = [JoinColumn(name = "vendor_settlement_id")],
inverseJoinColumns = [JoinColumn(name = "payment_id")],
)
val payments: List<Payment> = payments.sortedByDescending { it.paidAt }
Kotest withConstraintNow 이슈
kotest에서 테스트를 위해 OffsetDateTime.now()를 고정해야하는 경우들이 종종 있다. 그때 withConstraintNow함수를 사용하게 되는데 이때 InaccessibleObjectException을 마주하는 경우가 종종 있다.
withConstraintNow내부 코드를 보면 아래와 같이 mockStatic을 활용하는데 mockStatic에서 발생하는 이슈이지 않을까 추측된다.
inline fun <T, reified Time : Temporal> withConstantNow(now: Time, block: () -> T): T {
mockNow(now, Time::class)
try {
return block()
} finally {
unmockNow(Time::class)
}
}
@PublishedApi
internal fun <Time : Temporal> mockNow(value: Time, klass: KClass<Time>) {
mockkStatic(klass)
getNowFunctions(klass).forEach {
if(it.parameters.isEmpty()) {
every { it.call() } returns value
} else {
if(it.parameters[0].type.javaType == ZoneId::class.java) {
every { it.call(any<ZoneId>()) } returns value
} else {
every { it.call(any<Clock>()) } returns value
}
}
}
}
해당 이슈를 해결하기 위해서는 아래와 같이 Gradle 설정을 통해 해결할 수 있다.
// build.gradle.kts
tasks.withType<Test> {
... 생략
jvmArgs("--add-opens=java.base/java.time=ALL-UNNAMED")
}
이슈 참고: mockk/mockk#681
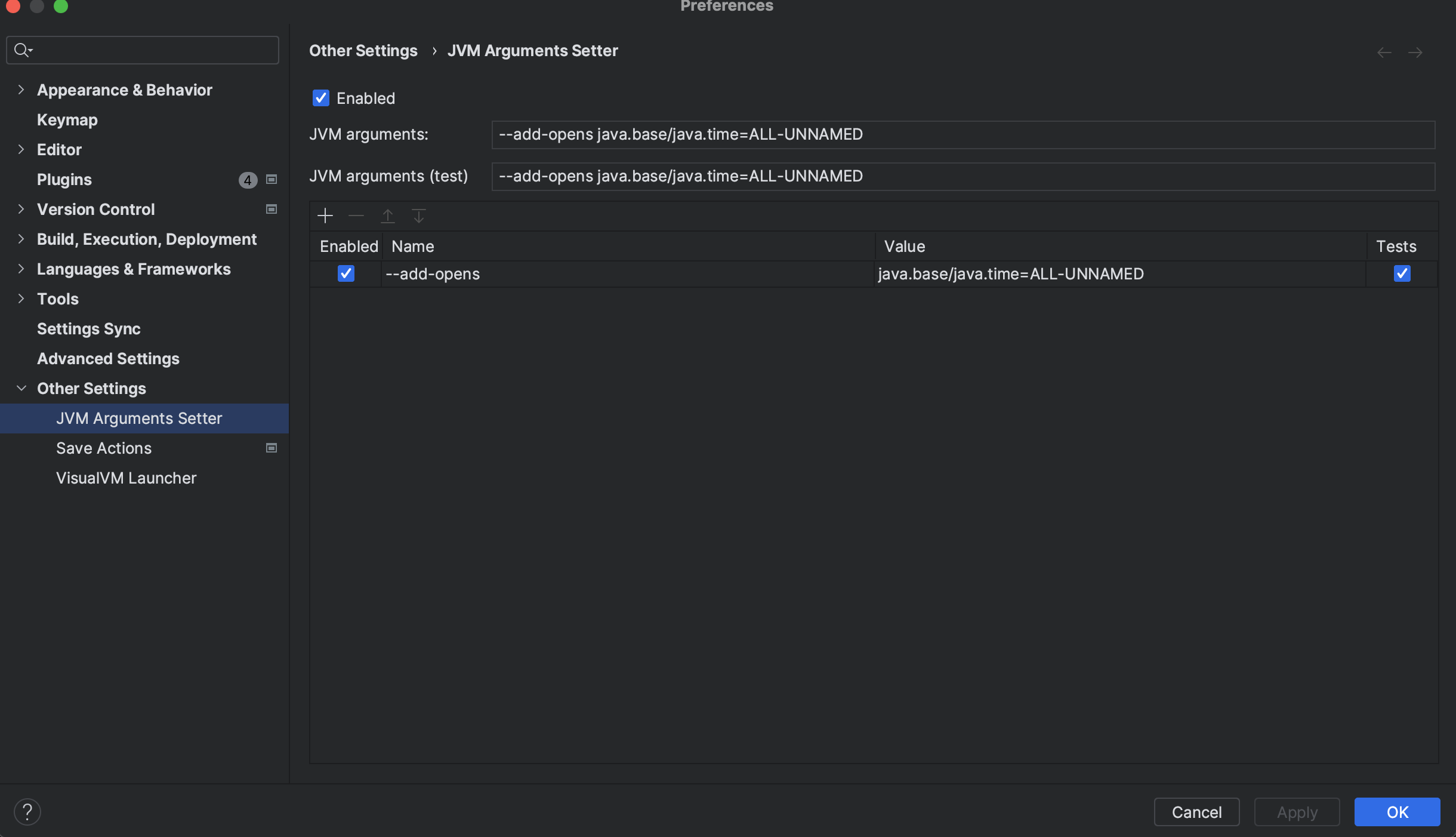
다만 이렇게 하는경우 Inetllij에서는 해당 옵션을 사용하지 못해 동일한 오류를 만날 수 있는데 jvm-argument 플로그인을 설치해서 위 설정값을 추가해주면 해결된다.
@Transactional(readOnly = true)
@Transactional(readOnly = true)를 적용해두면 읽기전용 Transaction에 대해 좀더 효율적인 방식으로 동작한다. 별거 아닌것 같지만 간단한 설정으로 성능적인 이득을 챙길 수 있으므로 적용해두면 좋다.
A boolean flag that can be set to true if the transaction is effectively read-only, allowing for corresponding optimizations at runtime. Defaults to false. This just serves as a hint for the actual transaction subsystem; it will not necessarily cause failure of write access attempts. A transaction manager which cannot interpret the read-only hint will not throw an exception when asked for a read-only transaction but rather silently ignore the hint.